[et_pb_section admin_label=”introduccion” transparent_background=”off” allow_player_pause=”off” inner_shadow=”off” parallax=”off” parallax_method=”off” padding_mobile=”off” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” make_equal=”off” use_custom_gutter=”off”][et_pb_row admin_label=”row”][et_pb_column type=”4_4″][et_pb_text admin_label=”Historia” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
El Centro de I+D de GeoInnova nace de la necesidad de ofrecer soluciones innovadoras que incorporen las últimas técnicas del estado-del-arte para los desafíos de nuestros clientes, es decir, la necesidad de explorar, aplicar y transferir tecnologías tales como Machine Learning, Inteligencia Artificial (IA), Cloud Computing, Integración de información, optimización matemática y automatización a nuestros clientes. Las técnicas por sí solas no son suficientes para agregar valor, por lo cual conocimientos de la fenomenología geológica minera y de procesos, así como el sentido del negocio minero, son fundamentales para los modelos o soluciones propuestas.
En GeoInnova desde el 2012 hemos incorporado técnicas de Machine Learning a problemáticas geológicas y mineras. Actualmente, apreciamos un alto interés de la industria minera por los temas de IA y presentamos algunas aplicaciones simples.
En esta publicación abordamos tres proyectos en los cuales hemos integrado técnicas de Machine Learning y Clustering:
- Predicción geológica espacial.
- Codificación de mapeos.
- Análisis de Clústeres utilizando datos Lito-geoquímicos.
[/et_pb_text][et_pb_text admin_label=”Problemáticas geológicas en el negocio Minero” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Problemáticas geológicas en el negocio Minero y su relación con técnicas de Machine Learning
Problemas de clasificación
Uno de los desafíos fundamentales de las áreas de geología es la caracterización geológica o construcción de información base para el desarrollo de proyectos y aseguramiento de producción en el negocio minero.
Clave es el mapeo geológico, entendido como una estimación y clasificación visual basada en diversos atributos geológicos utilizando conocimiento experto. En los últimos años, el mapeo geológico ha sido sometido a mayores exigencias, para explicar o dar respuesta a una serie de problemáticas geometalúrgicas, adicionalmente se han incorporado diferentes tipos de análisis: como análisis de ICP, información de datos espectrales, difracción de RX, análisis de imágenes. Esta combinación de información cuantitativa y mapeo, junto con la necesidad de clasificación lo hace un problema perfecto para el uso de técnicas de clasificación proveniente del área de la ciencia de datos.
Otra problemática corresponde al caso del modelamiento geológico, entendido como un problema de clasificación espacial, basado en información fragmentada de leyes y mapeos disponible en los sondajes u información adicional. Las técnicas de clasificación pueden ser adaptadas al contexto espacial y en conjunto con conocimiento geológico pueden ser un aporte para el modelamiento 3D.
Problemas de Identificación de Relaciones
La definición de unidades, relaciones y agrupaciones hoy se realiza por medio de herramientas de análisis exploratorio de datos estadísticas, tratando de buscar unidades o agrupaciones que permitan controlar las distribuciones de variables de recursos y geometalurgicas. La existencia de datos masivos y técnicas de clustering o de análisis de relaciones con Support Vector Machine (SVM) son una oportunidad de modernizar los análisis exploratorios tradicionales.
Antes de presentar algunos ejemplos de aplicación, presentamos una breve introducción a ciertas metodologías.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Clasificación y Algoritmos” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Clasificación y Algoritmos
Un problema de clasificación tradicional busca solucionar el problema de asignar a un objeto una o varias categorías. Se intenta generar un algoritmo que nos permita descubrir relaciones, patrones y tendencias entre los datos para clasificarlos en diferentes categorías, sin un modelo fenomenológico subyacente. Cuando utilizamos muestras etiquetadas de los datos, este tipo de algoritmos forman parte del subgrupo de Aprendizaje Supervisado.
[/et_pb_text][et_pb_image admin_label=”Figura – Algoritmos de Machine Learning” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura1.png” alt=”Diagrama de algoritmos de Machine Learning y ejemplos de aplicación” title_text=”Algoritmos de Machine Learning” show_in_lightbox=”on” url_new_window=”off” use_overlay=”off” animation=”left” sticky=”off” align=”center” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][et_pb_text admin_label=”Pie de Figura” background_layout=”light” text_orientation=”center” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Diagrama de algoritmos de Machine Learning y ejemplos de aplicación. Enlace a Imagen.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”2_3″][et_pb_text admin_label=”Algoritmos de Clasificacion” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Hoy en día los algoritmos de clasificación son utilizados de modo rutinario en otras industrias como banca, manufactura, retail, entretenimiento, entre otros, para aplicaciones como el diagnóstico de pacientes, detección de fraudes, detección de anomalías, sistemas de recomendación, etc.
En un clasificador, como entrada recibimos un vector de características X y como salida obtenemos un clasificador C(X), que nos indica la clase asignada a nuestro vector de entrada. Un clasificador convencional consta de los siguientes módulos:
[/et_pb_text][et_pb_text admin_label=”Etapas clasificación” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
- Preproceso: adquisición y filtrado de los datos.
- Extracción de características: cálculo de un vector de características.
- Clasificación: clasificación del vector de características.
[/et_pb_text][/et_pb_column][et_pb_column type=”1_3″][et_pb_image admin_label=”Figura – Diagrama de Clasificacion” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura2.png” alt=”Diagrama de Clasificación” title_text=”Diagrama de Clasificación” show_in_lightbox=”on” url_new_window=”off” use_overlay=”off” animation=”right” sticky=”off” align=”left” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][et_pb_text admin_label=”Pie de Figura” background_layout=”light” text_orientation=”center” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Diagrama de algoritmo de clasificación tradicional
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Tipos de algoritmos” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Además, estos pueden ser supervisados y no supervisados, los primeros aprenden con muestras etiquetadas previamente, mientras que los segundos aprenden con muestras no etiquetadas.
[/et_pb_text][et_pb_image admin_label=”Figura – Algoritmo supervisado vs no supervisado” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura3.gif” alt=”Algoritmo supervisado vs no supervisado” title_text=”Algoritmo supervisado vs no supervisado” show_in_lightbox=”off” url_new_window=”off” use_overlay=”off” animation=”fade_in” sticky=”off” align=”center” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][et_pb_text admin_label=”Pie de Figura” background_layout=”light” text_orientation=”center” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Entrenamiento supervisado vs no supervisado. Imagen obtenida desde diapositiva de asignatura Aprendizaje Automático y Reconocimiento de Formas, Dpto de Sistemas Informáticos y Computación, Universidad Politécnica de Valencia, España.
[/et_pb_text][et_pb_text admin_label=”Hiperplano separador” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
En general, se busca generar grupos que se separan en un espacio transformado y que sean disímiles entre ellos, esta clasificación se lleva a cabo por un hiperplano separador que represente los límites de decisión y que nos ayudan a clasificar los datos. De esta forma, los puntos que caen a cada lado del hiperplano se pueden atribuir a diferentes clases. La forma del hiperplano depende de las variables del modelo o la dimensionalidad del problema. Por ejemplo: si el número de variables a clasificar son dos, el hiperplano es una línea recta, en cambio, si son tres, el hiperplano es un plano en 2 dimensiones.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”1_2″][et_pb_text admin_label=”SVM: Un algoritmo de clasificación” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
SVM: Un algoritmo de clasificación
Support Vector Machine (SVM) es un caso de algoritmo de clasificación supervisado. Donde su objetivo es encontrar el hiperplano separador optimo que separa nuestros datos adecuadamente y nos permite hacer predicciones en forma precisa. Para esto, el algoritmo manipula los vectores de soporte, los cuales son puntos cercanos a un hiperplano que influyen en la posición y orientación de este.
[/et_pb_text][/et_pb_column][et_pb_column type=”1_2″][et_pb_text admin_label=”Encabezado de Figura” background_layout=”light” text_orientation=”center” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Hiperplano y margen para una SVM entrenada con 2 clases. Enlace a Imagen.
{kind=link}
[/et_pb_text][et_pb_image admin_label=”Figura – Margen en SVM” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura-4.png” alt=”Margen en SVM” title_text=”Margen en SVM” show_in_lightbox=”off” url_new_window=”off” use_overlay=”off” animation=”left” sticky=”off” align=”left” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”1_2″][et_pb_image admin_label=”Figura – Kernels” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura5.png” show_in_lightbox=”off” url_new_window=”off” use_overlay=”off” animation=”left” sticky=”off” align=”left” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid” alt=”Kernels ” title_text=”Kernels “]
[/et_pb_image][et_pb_text admin_label=”Pie de Figura” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Transformación de variables utilizando Kernels. Enlace a Imagen.
[/et_pb_text][/et_pb_column][et_pb_column type=”1_2″][et_pb_text admin_label=”Texto Kernels” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Las funciones discriminantes nos permiten movernos entre estos hiperplanos para asignar clases a nuestros datos. Si estas funciones no son linealmente separables, se utilizan Kernels, que permite representar las variables en un espacio alternativo de mayor dimensión donde nuestras funciones son linealmente separables.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Texto final modulo SVM” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
En GeoInnova hemos aplicado SVM a un problema de modelamiento geológico utilizando información histórica, además de considerar un Kernel inferido a través de los datos, utilizando los Variogramas.
[/et_pb_text][et_pb_text admin_label=”Texto”]
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Primeros pasos: Aplicación de SVM a la predicción geológica espacial (2012)” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” module_id=”app1″]
1. Primeros pasos: Aplicación de SVM a la predicción geológica espacial (2012)
[/et_pb_text][et_pb_divider admin_label=”Separador” color=”#ffffff” show_divider=”off” divider_style=”solid” divider_position=”top” hide_on_mobile=”on”]
[/et_pb_divider][et_pb_text admin_label=”Problema/Desafio” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Problema/Desafío
En el año 2012, nos propusimos como GNV incorporar técnicas de Machine Learning en nuestro quehacer de consultoría. Un primer ejercicio fue revisar la potencialidad de SVM vs técnicas tradicionales como Kriging de Indicadores para el modelamiento geológico.
En este desafío se estudió una modelo de aprendizaje tipo SVM en la aplicación de la reproducción de una imagen geológica de referencia sintética. Con el objetivo de predecir la extensión espacial de tipos de roca a partir de un porcentaje ínfimo de muestras utilizando SVM al modelamiento geológico.
En primer lugar, desde una imagen de referencia se muestrea aleatoriamente con diferentes densidades de información que varían en el rango de 0.01% a 0.1%.
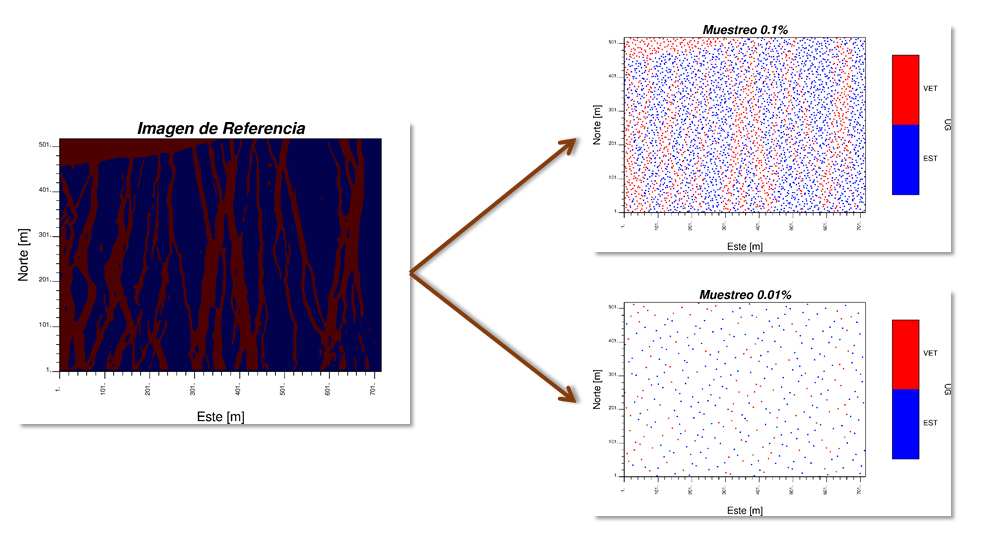
Imagen de referencia y resultado del muestreo
Una de las ideas claves del estudio fue sacar provecho a que las funciones de Kernel son de tipo definido positivo, lo cual aplica del mismo modo a las funciones base de caracterización espacial o modelos variográficos en Geoestadística. Con esto en mente nos propusimos generar un Kernel customizado usando nuestro tradicional Variograma.
[/et_pb_text][et_pb_text admin_label=”Metodologia” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Metodología
- IK: Kriging de indicadores infiere el Variograma de indicador, posteriormente se estima y se clasifican la pseudo probabilidad y es un estimador exacto.
- SVM1: se utilizó un Kernel con ajuste de parámetros C y Gamma; y una variable de distancias RBF para cada nivel de información (400 pruebas de validación cruzada).
- SVM2: C-SVM + Kernel inferido de los datos (Variograma).
Dado que los modelos variográficos son semidefinidos positivos, estos pueden ser usados como kernels en SVM, por lo que se usó el variograma anisotrópico del indicador. Es decir, el kernel usado a partir de la correlación espacial. Para el ajuste de parámetro del C se utilizaron 200 pruebas.
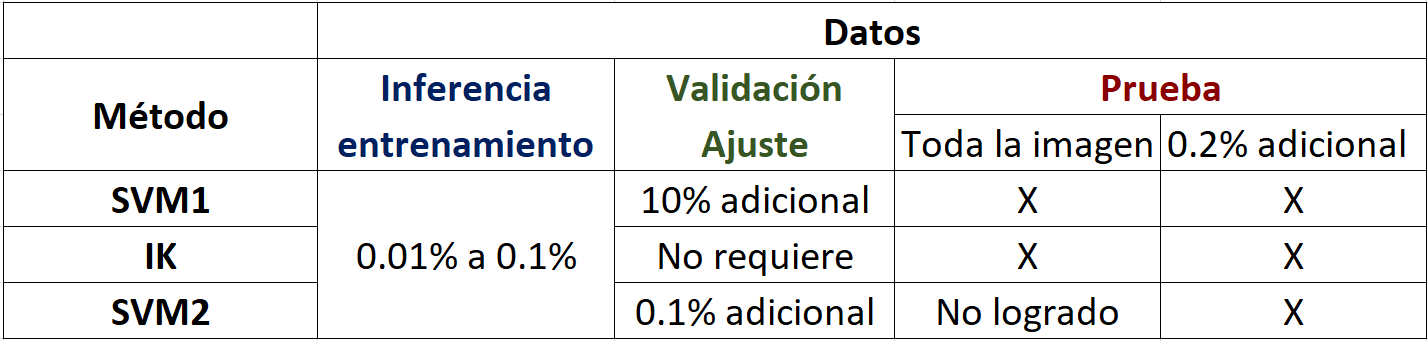
Tabla con configuración utilizada para los diferentes métodos.
Para cada tipo de algoritmo las etapas fueron los siguientes:
- Para IK se interpola mediante Kriging todos los puntos de la imagen.
- Para SVM se ajustan, se entrenan y se aplica validación cruzada, posteriormente se predice los puntos restantes.
[/et_pb_text][et_pb_text admin_label=”Resultados” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Resultados
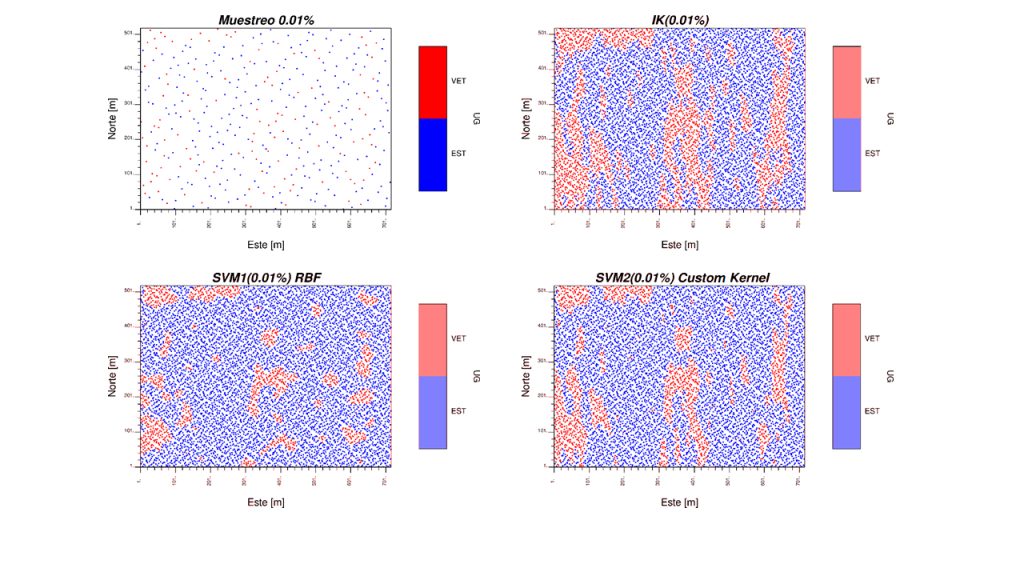
Resultados en 0.2% de los datos
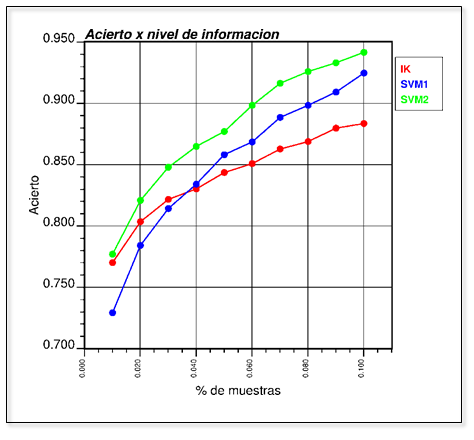 Al analizar el resultado se tiene que cuando la densidad es muy baja el IK supera al SVM1, pero posteriormente cuando el nivel de información es alto, el SVM1 aumenta la predicción. Sin embargo, al usar SVM2 usando un variograma de indicadores como kernel, este es siempre superior en acierto a los otros 2 métodos, lo cual demuestra que la inferencia de Kernels a partir de los datos o el fenómeno, agrega valor, robusteciendo los modelos predictivos frente a aproximaciones casi de fuerza bruta de mejora de predicción.
Al analizar el resultado se tiene que cuando la densidad es muy baja el IK supera al SVM1, pero posteriormente cuando el nivel de información es alto, el SVM1 aumenta la predicción. Sin embargo, al usar SVM2 usando un variograma de indicadores como kernel, este es siempre superior en acierto a los otros 2 métodos, lo cual demuestra que la inferencia de Kernels a partir de los datos o el fenómeno, agrega valor, robusteciendo los modelos predictivos frente a aproximaciones casi de fuerza bruta de mejora de predicción.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”SVM aplicado a codificación de mapeos faltantes (2014)” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” module_id=”app2″]
2. SVM aplicado a codificación de mapeos faltantes (2014)
[/et_pb_text][et_pb_text admin_label=”Problema\Desafio” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Problema/desafío
Se requería construir un modelo geológico de zonas minerales en los sulfuros, con información histórica de leyes y mapeos. Como se había adoptado distintos criterios de mapeos durante la historia de proyecto y distintas informaciones, los datos eran mayoritariamente heterotópicos. Eran más de 200.000 metros de sondajes por lo que resultaba impensable en remapear.
[/et_pb_text][et_pb_text admin_label=”Datos” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Datos
Las fuentes de información eran:
- Leyes: de cobre total (CuT), cobre soluble (CuS) y cobre soluble con ácido férrico CuSFe.
- Mapeos de relativo de especies de sulfuros y volumen de sulfuros a nivel de soporte de ley.
- Zona mineral: mapeo de zonas minerales sulfuros secundario y primarios.
Solo el 11 % de la data tenía los 3 tipos de fuentes y eran coherentes entre ellas, ejemplo: sulfuro secundario fuerte tenía que presentar leyes mayores a 0.6% de CuT, mapeo relativo de calcosina mayor a 65 y 40% razón de CusFe/CuT.
El nivel de heterotopía de la base de datos cambia significativamente dependiendo de las variables, por ejemplo, el 100% de la data tenía CuT y en cambio CuSFe solo estaba presente en el 70% de la data.
[/et_pb_text][et_pb_text admin_label=”Metodologia” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Metodología y aplicación de SVM
- En primer lugar, se completaron las bases de datos con cosimulación heterotópicas con la información tipo i) y ii).
- SVM jerárquico: se generó un clasificador binario jerárquico usando SVM como variables de entrada, CuT, CusFe, CuS, % de especies minerales y coordenadas. Para definir la jerarquía se utilizaron los conceptos geológicos asociados a la mineralogía hipógena, supérgena de modo de orientar el clasificador basado en la fenomenología. Se separó la base de datos de entrenamiento, una de validación y test mediante validación cruzada para analizar la predictibilidad de las zonas minerales.
Se validó la codificación realizada con SVM junto a la información de pozos de tronadura. Adicionalmente se validó el resultado visualmente por parte de un geólogo que tenía experiencia en depósito y que había mapeado una cantidad relevante. Además, el cliente también validó algunos sondajes con remapeo.
[/et_pb_text][et_pb_text admin_label=”Resultados y Aprendizajes” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Resultados

La figura superior muestra los sondajes con los mapeos de zonas minerales y en blanco se presentan las trazas de los sondajes sin clasificación. La segunda muestra el resultado del algoritmo aplicado y la tercera figura es la validación visual entre zonas minerales en los sondajes y los pozos de tiro.
Aprendizajes
Las técnicas de Machine Learning tiene gran aplicabilidad en bases de datos históricas con información disimiles en características para clasificar códigos. En este caso permite integrar y completar el mapeo 3D con coherencia espacial.
Estos modelos permiten predecir atributos geológicos con coherencia espacial. Se puede aplicar para QA, adicionalmente arroja métricas de confiabilidad de la clasificación lo cual también es clave para orientar campañas de remapeo o mejorar los criterios de mapeo geológicos en los equipos de caracterización.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Análisis de Clústeres utilizando datos Lito-geoquímicos de ICP (2019)” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” module_id=”app3″]
3. Análisis de Clústeres utilizando datos Lito-geoquímicos de ICP (2019)
El análisis de clústeres nos ayuda a buscar relaciones entre un conjunto de datos y definir si existen clases o clústeres en que puedan ser agrupados. Uno de los algoritmos para generar estos clústeres es el Clustering Aglomerativo.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”1_2″][et_pb_text admin_label=”Intro Clustering Aglomerativo” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
El Clustering Aglomerativo es un tipo de agrupamiento jerárquico no supervisado que busca agrupar los datos en clústeres basados en su similitud y en forma jerárquica. El algoritmo comienza tratando a todos los datos como parte de un clúster, y a medida que avanza va uniendo pares de clústeres hasta que finalmente solo existe un único gran clúster. Los parámetros de entrada del algoritmo que nos interesan en esta aplicación son: el número de clústeres, métrica de distancia entre muestras y el criterio de vinculación.
[/et_pb_text][/et_pb_column][et_pb_column type=”1_2″][et_pb_image admin_label=”Figura – Dendograma Clustering” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura11.png” alt=”Dendograma Clustering Jerárquico” title_text=”Dendograma Clustering Jerárquico” show_in_lightbox=”off” url_new_window=”off” use_overlay=”off” animation=”right” sticky=”off” align=”center” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][et_pb_text admin_label=”Pie de Figura” background_layout=”light” text_orientation=”center” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Dendograma Clustering Aglomerativo.Enlace a Imagen.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Problema/Desafío” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Problema/Desafío
Inicialmente se contaba con datos de litología y alteración agrupada en una base de datos de sondajes, la cual, si bien era masiva en datos, el número de litologías y alteraciones era bajo. Adicionalmente, se tenía una gran cantidad de análisis de ICP disponibles. La idea central era evaluar si los datos lito-geoquímicos de ICP eran consistentes con las codificaciones de litología existentes, y si daban cuenta de facies o separaciones geológicas en el depósito y evaluar potencial impacto en variables geometalúrgicas.
[/et_pb_text][et_pb_text admin_label=”Datos” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Datos
En la aplicación de Clustering Aglomerativo se contaba con 338.785 muestras agrupadas en 52 variables de ICP, una variable categórica de litología y las correspondientes coordenadas espaciales de los sondajes. De las variables de ICP seleccionamos 32 de ellas para generar un proceso de clustering jerárquico aglomerativo.
[/et_pb_text][et_pb_text admin_label=”Metodologia” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Preprocesamiento y Aplicación de Clustering
Como primer paso se normalizan los datos eliminando la media de estos y escalando según la varianza unitaria, corrección afín, para evitar que los datos que tengan ordenes de magnitud mayor que otros dominen la función objetivo.
Posteriormente se aplica el algoritmo de Clustering Aglomerativo utilizando diferente número de clústeres como parámetro de entrada. La métrica de distancia utilizada fue la distancia euclidiana entre muestras y como criterio de vinculación el que disminuye la varianza entre los clústeres que serán fusionados.
[/et_pb_text][et_pb_text admin_label=”Resultados” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Resultados
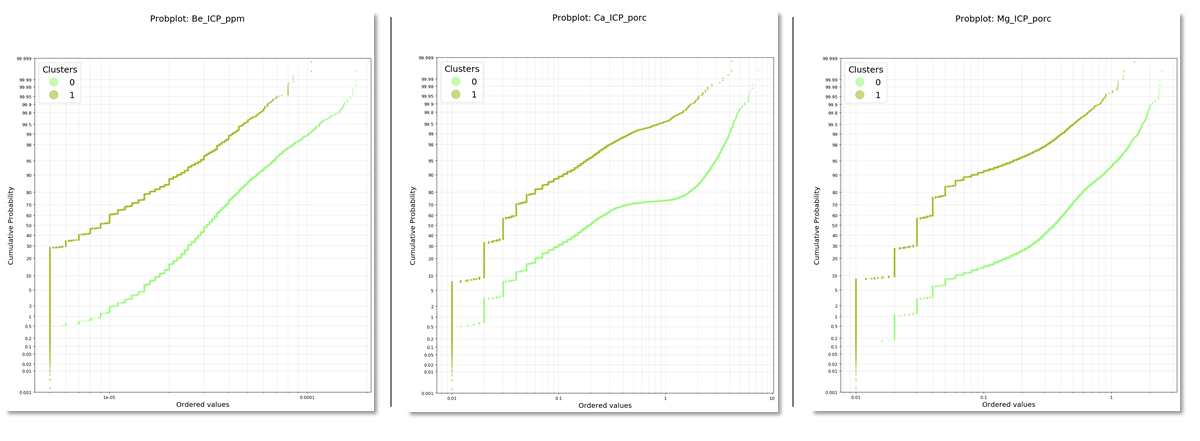 Probplot de las variables de ICP: Be, Ca, Mg, para un modelo con 2 clústeres
Probplot de las variables de ICP: Be, Ca, Mg, para un modelo con 2 clústeres
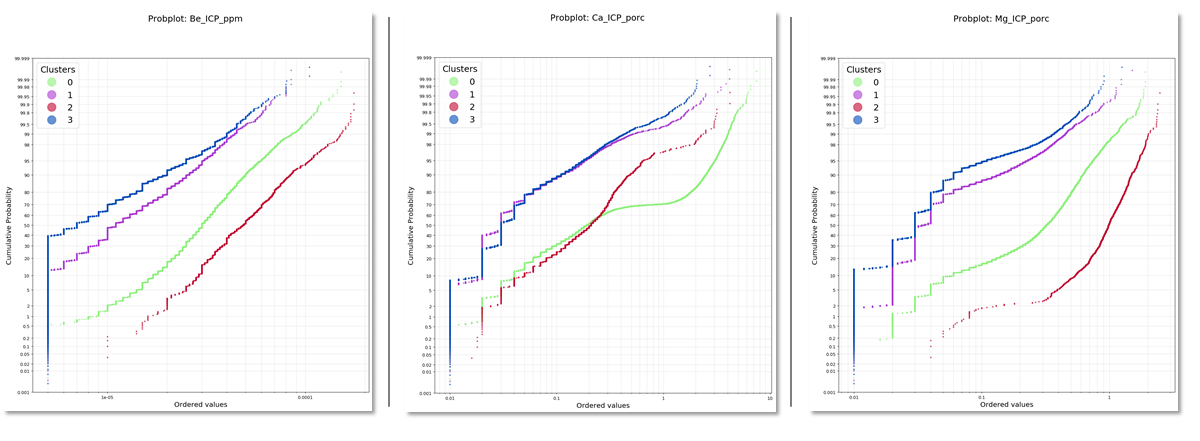
Probplot de las variables de ICP: Be, Ca, Mg para un modelo con 4 clústeres
En este caso comparamos las variables ICP en función de los clústeres generados. Nos damos cuenta de que existen variables que influyen en mayor medida en la generación de los clústeres.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”1_3″][et_pb_text admin_label=”Texto” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
En términos espaciales se aprecia que al configurar dos clústeres se tienden a marcar el centro del depósito vs la periferia reflejando dominios de mineralización, alteración y litología diferentes. Es interesante ver como al aumentar los clústeres se confirman los grandes dominios de lito y alteración modelados, pero a la vez develen existencias de facies o características geoquímicas distintas al interior de estas.
[/et_pb_text][/et_pb_column][et_pb_column type=”1_3″][et_pb_image admin_label=”Figura – Clustering de ICP para diferentes variables” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura14.png” alt=”Resultados Clustering de ICP para diferentes variables” title_text=”Resultados Clustering de ICP para diferentes variables” show_in_lightbox=”off” url_new_window=”off” use_overlay=”off” animation=”right” sticky=”off” align=”center” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][/et_pb_column][et_pb_column type=”1_3″][et_pb_image admin_label=”Figura – Clustering de ICP para diferente cantidad de Clusteres” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura15.png” alt=”Resultados Clustering de ICP para diferente cantidad de Clusteres” title_text=”Resultados Clustering de ICP para diferente cantidad de Clusteres” show_in_lightbox=”off” url_new_window=”off” use_overlay=”off” animation=”right” sticky=”off” align=”left” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Encabezado de Figura” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Un ejemplo de confirmación es como naturalmente un techo de sulfato aparece marcado en un límite en profundidad. Cómo se ilustra a continuación.
[/et_pb_text][et_pb_image admin_label=”Figura – ICP Clustering 3D” src=”https://geoinnova.cl/wp-content/uploads/2020/05/Figura16.png” alt=”Resultado ICP Clustering 3D” title_text=”Resultado ICP Clustering 3D” show_in_lightbox=”off” url_new_window=”off” use_overlay=”off” animation=”fade_in” sticky=”off” align=”center” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][et_pb_text admin_label=”Texto” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Estos clústeres son usados para evaluar necesidad futura de modelamiento, profundización de conocimiento y evaluación de controles sobre datos geometalúrgicos.
[/et_pb_text][et_pb_text admin_label=”Aprendizajes” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Aprendizajes
Existen oportunidades importantes para la caracterización espacial utilizando algoritmos de clustering supervisado o no supervisado. El uso de estas técnicas en conjunto con las aproximaciones clásicas de geoquímica permite un incremento en el conocimiento geológico y profundización de la conceptualización genética del mismo.
En términos de modelamiento, al combinar con información espacial de las variables permite mejorar los controles en modelos geológicos, de recursos y geometalúrgicos, aumentando su precisión y predictibilidad, con la consecuente mejora para el negocio minero.
[/et_pb_text][et_pb_text admin_label=”Implementacion” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Implementación
La implementación fue hecha en Python utilizando las librerías Pandas, Numpy y SkLearn. Para realizar los gráficos de Probplot se utilizó la librería Probscale y Matplotlib.
Repositorio GitHub con el código fuente
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Comentario finales” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Comentarios finales
Los algoritmos de inteligencia artificial tienen un gran potencial de aplicación en toda la cadena de valor del negocio minero. Si bien estos no tienen hipótesis subyacentes con respecto a la fenomenología, si se incorpora y combina con conocimiento de geología, minería, procesos y geoestadística, los resultados pueden ser muy útiles.
El equipo de GeoInnova a diario encuentra mayores potenciales de aplicación de estas técnicas de Machine Learning, y no solo en geología, sino también en procesos, en la cuantificación de calidad de concentrado, consumo de agua y en etapas de procesos de espesamiento/sedimentación, entre otras.
La adecuada implementación de IA en minería requiere una adaptación cultural de las organizaciones, en donde se pueda integrar a los equipos de trabajo habituales, profesionales con estos conocimientos. Esto ha sido clave en GeoInnova, la integración del equipo de I+D de Cómputo científico y Data Science con los especialistas de Geología y Minería para obtener resultados con sentido geológico y acorde al negocio.
Las empresas mineras y el mundo corporativo deben recordar que las innovaciones en general se llevan a cabo en los márgenes de los ecosistemas y por lo tanto, la interacción con proveedores tecnológicos es clave para acelerar la adopción de estas técnicas en la industria minera.
[/et_pb_text][et_pb_text admin_label=”Texto” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Autores:
Cristobal Barrientos  , Alejandro Cáceres , Andrés Sandoval , Rodrigo Riquelme
, Alejandro Cáceres , Andrés Sandoval , Rodrigo Riquelme
[/et_pb_text][et_pb_text admin_label=”Texto” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Equipo I+D:
Alan Toledo  , Manuel Hoffhein , Javier Ortiz , Cristóbal Barrientos .
, Manuel Hoffhein , Javier Ortiz , Cristóbal Barrientos .
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]