[et_pb_section admin_label=”section”][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_slider admin_label=”Deslizador” show_arrows=”on” show_pagination=”on” auto=”on” auto_speed=”3000″ auto_ignore_hover=”on” parallax=”off” parallax_method=”off” remove_inner_shadow=”off” background_position=”default” background_size=”contain” hide_content_on_mobile=”off” hide_cta_on_mobile=”off” show_image_video_mobile=”off” custom_button=”off” button_letter_spacing=”0″ button_use_icon=”default” button_icon_placement=”right” button_on_hover=”on” button_letter_spacing_hover=”0″]
[et_pb_slide background_position=”default” background_size=”contain” background_color=”rgba(255,255,255,0)” use_bg_overlay=”off” use_text_overlay=”off” alignment=”center” background_layout=”dark” allow_player_pause=”off” text_border_radius=”3″ header_font_select=”default” header_font=”||||” body_font_select=”default” body_font=”||||” custom_button=”off” button_font_select=”default” button_font=”||||” button_use_icon=”default” button_icon_placement=”right” button_on_hover=”on” background_image=”https://geoinnova.cl/wp-content/uploads/2020/08/banner_coestim-2.png”]
[/et_pb_slide][et_pb_slide background_position=”default” background_size=”contain” background_color=”rgba(255,255,255,0)” use_bg_overlay=”off” use_text_overlay=”off” alignment=”center” background_layout=”dark” allow_player_pause=”off” text_border_radius=”3″ header_font_select=”default” header_font=”||||” body_font_select=”default” body_font=”||||” custom_button=”off” button_font_select=”default” button_font=”||||” button_use_icon=”default” button_icon_placement=”right” button_on_hover=”on” button_link=”https://drive.google.com/file/d/1nMtRdOQZ8fYPQ8W8z0DJLPyTzAv67Ciw” background_image=”https://geoinnova.cl/wp-content/uploads/2020/08/banner_coestim_paso1.png”]
[/et_pb_slide][et_pb_slide background_position=”default” background_size=”contain” background_color=”rgba(255,255,255,0)” use_bg_overlay=”off” use_text_overlay=”off” alignment=”center” background_layout=”dark” allow_player_pause=”off” text_border_radius=”3″ header_font_select=”default” header_font=”||||” body_font_select=”default” body_font=”||||” custom_button=”off” button_font_select=”default” button_font=”||||” button_use_icon=”default” button_icon_placement=”right” button_on_hover=”on” background_image=”https://geoinnova.cl/wp-content/uploads/2020/08/banner_coestim_paso2.png”]
[/et_pb_slide][et_pb_slide background_position=”default” background_size=”contain” background_color=”rgba(255,255,255,0)” use_bg_overlay=”off” use_text_overlay=”off” alignment=”center” background_layout=”dark” allow_player_pause=”off” text_border_radius=”3″ header_font_select=”default” header_font=”||||” body_font_select=”default” body_font=”||||” custom_button=”off” button_font_select=”default” button_font=”||||” button_use_icon=”default” button_icon_placement=”right” button_on_hover=”on” background_image=”https://geoinnova.cl/wp-content/uploads/2020/08/banner_coestim_paso3.png”]
[/et_pb_slide]
[/et_pb_slider][et_pb_image admin_label=”Imagen” src=”https://geoinnova.cl/wp-content/uploads/2020/08/unnamed.png” show_in_lightbox=”off” url=”https://drive.google.com/file/d/1nMtRdOQZ8fYPQ8W8z0DJLPyTzAv67Ciw/edit” url_new_window=”on” use_overlay=”off” animation=”off” sticky=”off” align=”center” force_fullwidth=”off” always_center_on_mobile=”on” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[/et_pb_image][et_pb_text admin_label=”Texto” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Requisitos de Hardware y Software
- Contar con tarjeta de video dedicada.
- Drivers/Controladores de la tarjeta de video actualizados.
- 8GB de momoria RAM o más.
- Windows 8.1 o superior.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”row”][et_pb_column type=”4_4″][et_pb_video admin_label=”Vídeo” src=”https://youtu.be/thixnq7Wu6k”]
[/et_pb_video][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”1_2″][et_pb_video admin_label=”Vídeo” src=”https://youtu.be/cZl7eMDQbGY”]
[/et_pb_video][/et_pb_column][et_pb_column type=”1_2″][et_pb_video admin_label=”Vídeo” src=”https://youtu.be/sYb-Pu0pUm8″]
[/et_pb_video][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”1_4″][/et_pb_column][et_pb_column type=”1_2″][et_pb_video admin_label=”Vídeo” src=”https://youtu.be/V2OBijA2JDc”]
[/et_pb_video][/et_pb_column][et_pb_column type=”1_4″][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_text admin_label=”Texto” background_layout=”light” text_orientation=”center” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Para mayor información de CoEstim y del proceso de Coestimación revisa el contenido de esta página.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila”][et_pb_column type=”4_4″][et_pb_accordion admin_label=”Acordeón” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
[et_pb_accordion_item title=”Coestimación”]
El cokriging es la extensión multivariable del kriging y se utiliza principalmente con 2 objetivos: cuando existe una variable A, submuestreada, correlacionada con una variable B, más muestreada (heterotopía), y se busca explotar esta relación para estimar en zonas con poca información de la variable A, o cuando se tienen dos o más variables correlacionadas y se desea conservar en cierta medida esta relación.
El cokriging implementado asume un modelo lineal de corregionalización para el modelamiento conjunto de los variogramas simples y cruzados.
Si dos variables están correlacionadas y son estimadas por kriging de manera independiente, es decir, parámetros de búsquedas y variogramas distintos, no se asegura que la relación entre las variables se conserve.
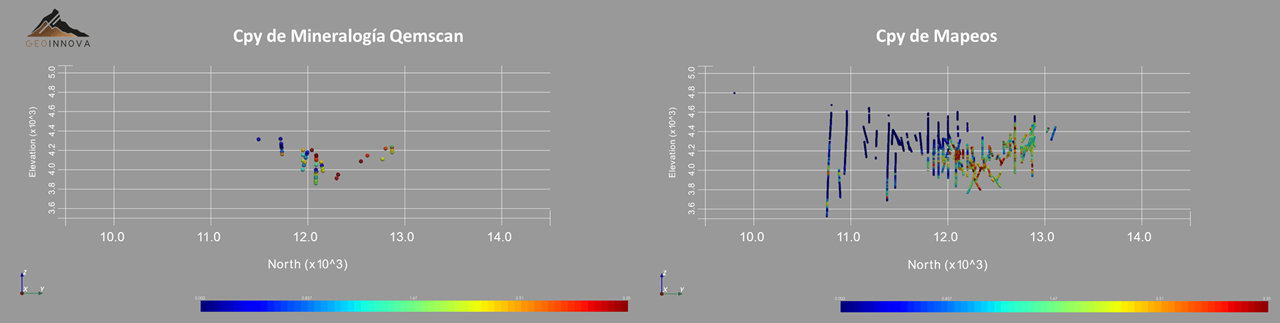
Cokriging tiene muchísimas aplicaciones en geología, geofísica y geometalurgia, en donde test baratos masivos tales como ICP, NIR o mapeos pueden ser combinados con test metalúrgicos escasos y caros, para coestimar y predecir el comportamiento de porcentaje de mineralogías, recuperaciones, variables de conminución, velocidades de sedimentación, yield stress, entre muchas otras. Un ejemplo es el que se muestra a continuación, donde para estimar calcopirita en un depósito existen unas pocas muestras con análisis qemscan, mientras que la información asociada a mapeos de mineralogía es mucho más densa.
Actualmente esta metodología de estimación no está altamente difundida en la industria minera por la falta de softwares que incorporen este método, los que en general presentan tiempos de ejecución altos.
Buscamos ayudar a familiarizar a la industria con este tipo de técnicas multivariables muy útiles en el contexto de geociencias, junto con enfrentar los tiempos de cálculos asociados a los sistemas multivariables.
Considerando estas condiciones y sus múltiples aplicaciones es que decidimos aventurarnos con cokriging.
[/et_pb_accordion_item][et_pb_accordion_item title=”CoEstim”]
CoEstim es un software creado por el Centro de I+D de GeoInnova con el apoyo de Corfo. Su motivación principal es la creación de una herramienta de coestimación que saque el máximo provecho al hardware donde es ejecutado, en especial a la tarjeta de procesamiento gráfico que contenga (GPU en sus siglas en inglés).
Características principales de Coestim:
- Lectura y escritura de archivos .csv.
- Estimación multivariable bajo modelo LMC.
- Cokriging ordinario y simple con media global o local.
- Adaptado para manejo de bases de datos heterotópicas (distinto N por cada variable).
- Acepta estimaciones de varias unidades de estimación simultáneamente.
- Incorpora estimaciones sucesivas de radios incrementales (pasadas).
- Restricciones aseguramiento de interpolación muestras por sondajes y octantes.
- Capping y trimming limits.
- Valor por defecto por unidad para bloques no estimados.
- Permite compartir muestras entre unidades.
- Estimación en nodos o bloques. Se puede cargar grilla parcial o completa.
- Incorpora visualizador 3D para verificación de resultados.
Para el modelamiento variográfico, el centro de I+D próximamente liberara un software de cálculo de variogramas y ajuste semiautomático basado en Optimización por enjambre de partículas usando computo por GPU (Variograma).
Cimientos
El algoritmo base de CoEstim fue obtenido del programa KT3D y las librerías adicionales de GSLIB, sin embargo, ciertos procesos de este algoritmo fueron optimizados y otros fueron completamente reemplazados.
La convención que mantiene CoEstim de GSLIB es la definición de sus ángulos, esto es, se considera el eje Y como eje principal y los ángulos de Euler rotan en torno a los ejes ZXY. Esta convención se utiliza en los ángulos de búsqueda de muestras cercanas (búsqueda global o local) y en los ángulos de las estructuras de los variogramas.
Optimizaciones
Como mencionamos anteriormente, el algoritmo base fue optimizado para lograr un mejor rendimiento. Una de las optimizaciones más fuertes incorporadas fue la implementación del corazón de la estimación (búsqueda de vecinos, matriz de covarianza y su resolución) sobre GPU. Esta implementación bajó fuertemente los tiempos de ejecución del algoritmo llegando a ser hasta 10 veces más rápido que otros softwares comerciales sobre depósitos medianos, y hasta 5 veces más rápido sobre depósitos de gran tamaño.
Otra optimización se realizó sobre la estructura para el ordenamiento. GSLIB utiliza “Super Block Search” para ordenar tanto el modelo de bloques y la base de datos, para luego sobre ella realizar la búsqueda de muestras cercanas de cada bloque iterando por cada uno de ellos. Nuestra optimización se da durante la creación de esta estructura y su utilización en generar paquetes de bloques a estimar que son enviados a la GPU para estimar más de un bloque a la vez.
También se utilizaron algoritmos de ordenamiento óptimos y estructuras de datos para realizar tareas auxiliares a la estimación y que aceleraron el proceso.
[/et_pb_accordion_item][et_pb_accordion_item title=”CoEstim User Interface”]
CoEstim primero nace como un programa ejecutable por línea de comandos, pero el Centro de I+D de GeoInnova se ha dedicado a generar una interfaz para la utilización de CoEstim de manera más amigable con el usuario.
Esta interfaz se divide en las partes necesarias para llevar a cabo la coestimación: definición del modelo de bloques, definición de la base de datos, definición de parámetros de búsqueda y definición de variogramas (global o por unidad de estimación).
Cabe señalar que los archivos soportados por CoEstim consisten en modelos de bloques y bases de datos .csv con formato de coordenadas X,Y,Z más las columnas con las variables de interés.
[/et_pb_accordion_item][et_pb_accordion_item title=”UI: Bases de Datos”]
Base de datos
En este módulo se puede seleccionar el archivo que será utilizado como base de datos. Se debe seleccionar con el botón “Select”. Al elegir un archivo en el cuadro de diálogo, se procede a cargar sus cabeceras. Para agregar los tipos de columnas necesarios, se debe hacer clic en “Add Column”, que desplegará una ventana donde se listan las cabeceras del archivo.
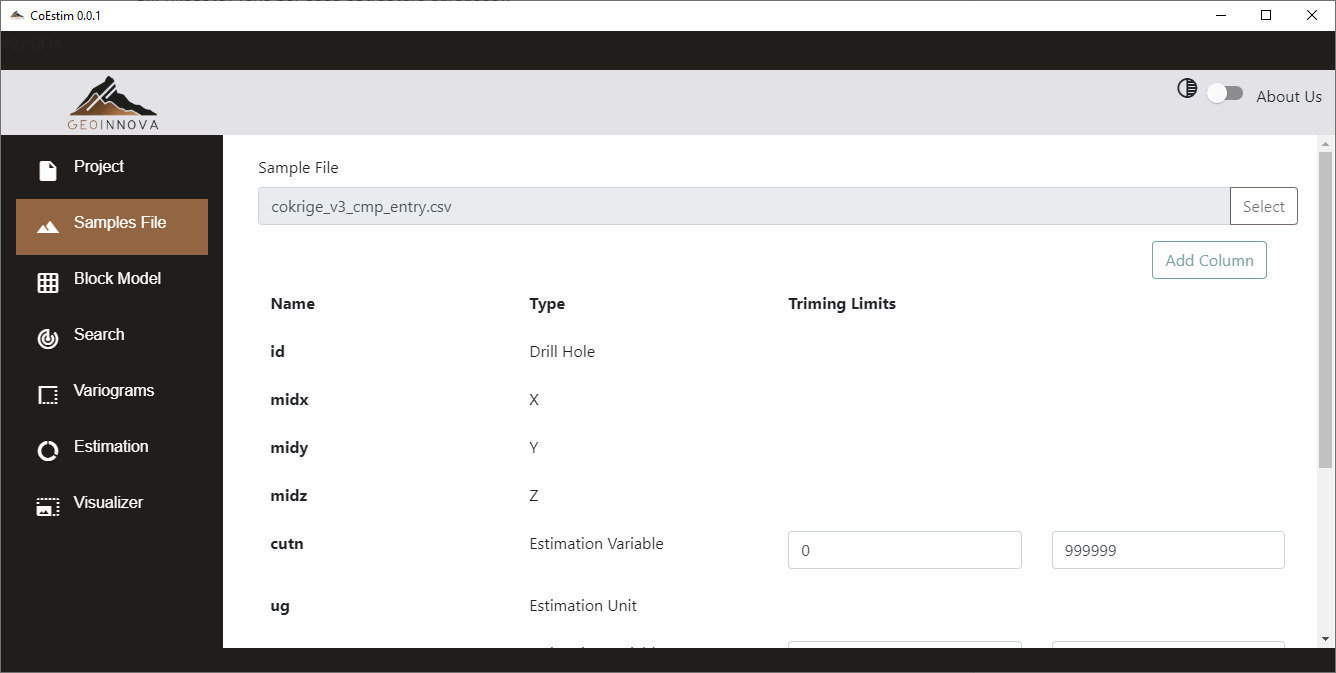
Por cada cabecera se despliegan tipos que se requieren: X, Y, Z, ID de sondaje (Drillhole ID), Geología (Estimation Unit), y variables (Estimation Variable). Es obligatorio establecer las cabeceras para X, Y, Z, así como al menos escoger una cabecera como variable. Las cabeceras para el ID de los sondajes y la Geología no es necesario establecerlas, pero se debe considerar que: si no se establece el ID de sondajes, no se puede hacer filtro por sondaje en la búsqueda; si no se establece Geología (Estimation Unit) en la base de datos, tampoco podrá hacerlo en el modelo de bloques y se considerará una sola unidad de estimación para todos los bloques y todas las muestras.
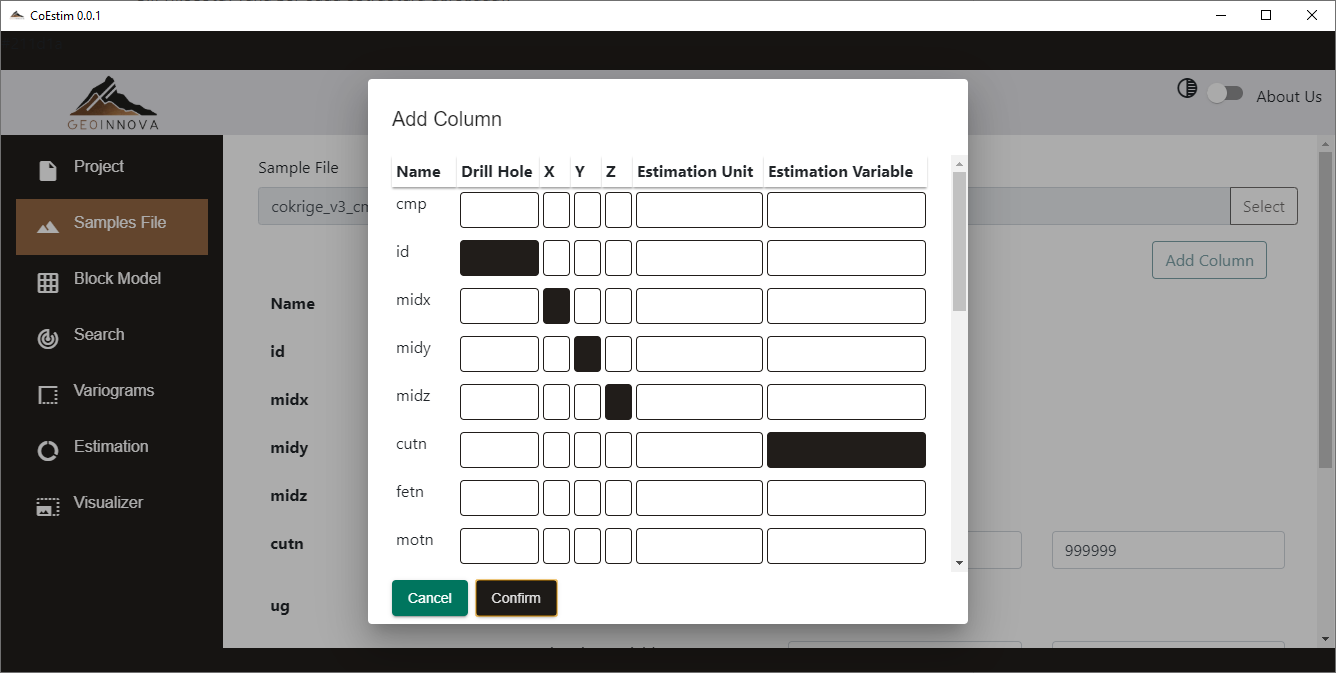
Una vez seleccionadas las cabeceras y haciendo clic en “Confirm”, la vista principal muestra las cabeceras seleccionadas con su respectivo tipo. Para las cabeceras del tipo “Estimation Variable” se muestra además los campos para establecer los límites de corte en los valores de esas variables.
[/et_pb_accordion_item][et_pb_accordion_item title=”UI: Modelo de Bloques”]
Modelo de Bloques
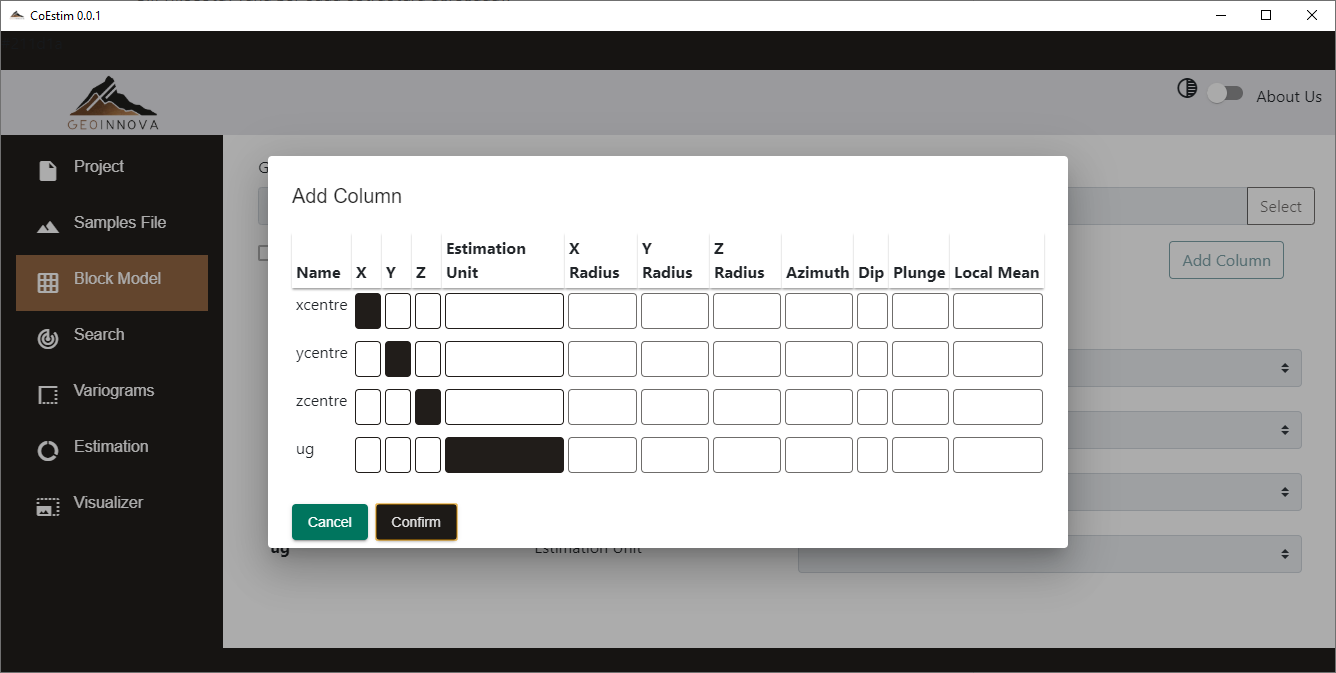
Este módulo permite cargar el archivo de modelo de bloques que será co-estimado. Al igual que en el módulo anterior, luego de cargadas las cabeceras del archivo, se deben agregar columnas con el botón “Add Column” y seleccionar los tipos de cabecera necesarios, en este caso X, Y, Z y Geología (Estimation Unit), siendo las primeras tres obligatorias y la Geología opcional, cumpliendo las mismas condiciones antes mencionadas si no se establece.
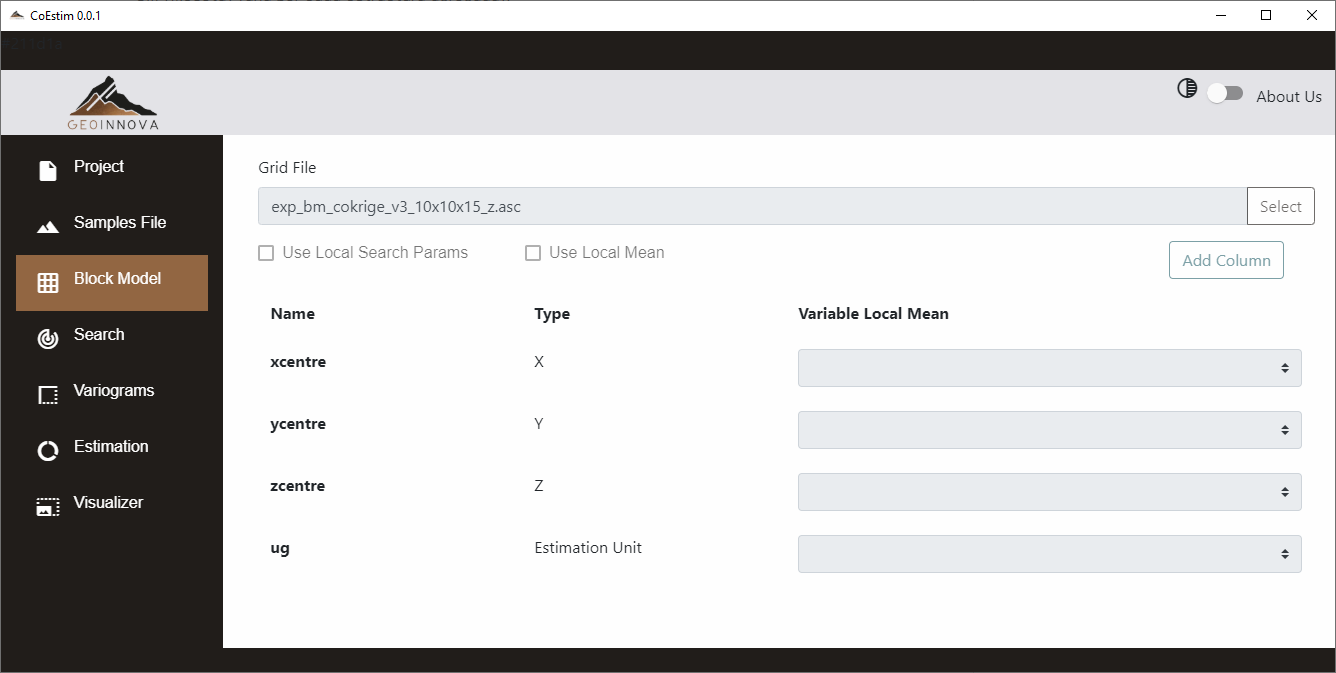
También se pueden establecer tipos de cabecera adicionales: X Radius, Y Radius, Z Radius, Azimuth, Dip y Plunge. Estos son utilizados para la búsqueda local. También se puede definir una media local (Local Mean) para ser utilizada en la ejecución de Cokrige Simple. Estos tipos de cabecera adicionales no están disponibles para ser seleccionadas en la versión de prueba.
[/et_pb_accordion_item][et_pb_accordion_item title=”UI: Búsqueda”]
Parámetros de Búsqueda
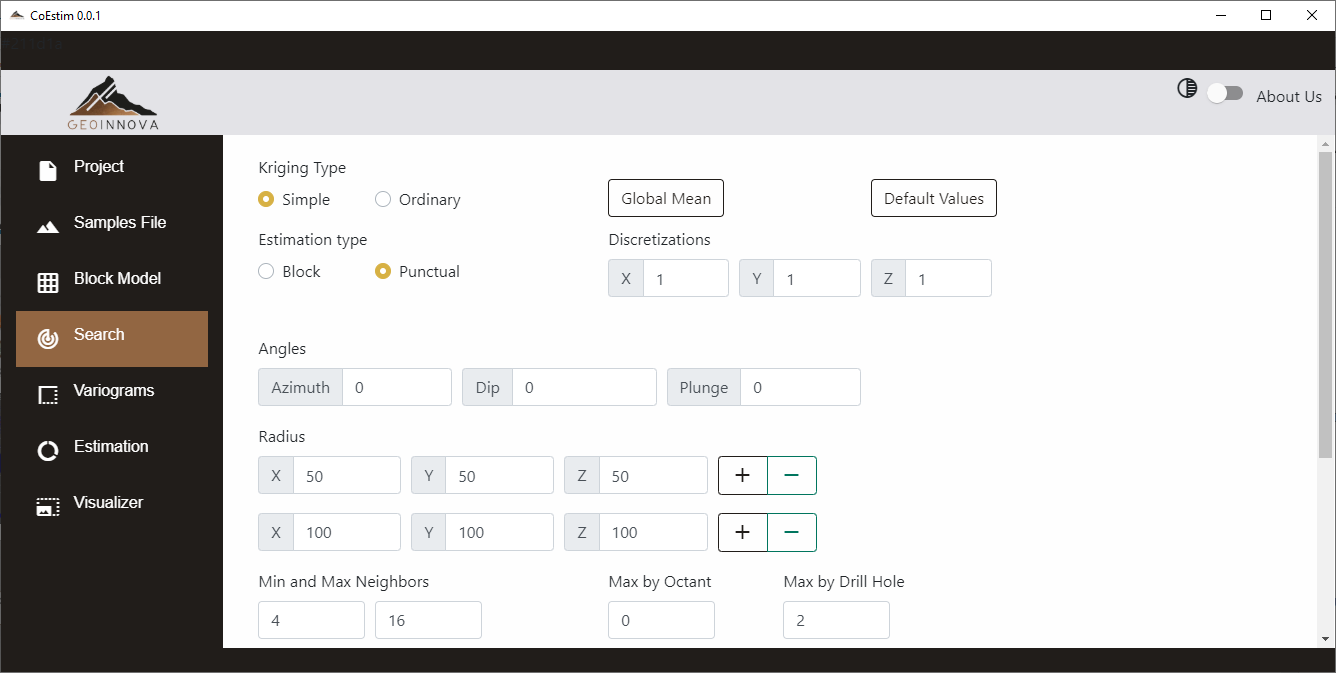
Este módulo contiene todos los parámetros relacionados con la búsqueda de la vecindad de datos de los bloques para realizar la co–estimación.
En esta interfaz podemos configurar:
- Tipo de Cokrige:
- Medias globales de las variables.
- Valores por defecto de las variables (en caso de no estimar en el bloque).
- Tipo de estimación:
- Puntual: se debe establecer la discretización de los bloques.
- Block: se debe establecer el tamaño de los bloques.
- Ángulos de la búsqueda.
- Radios de búsqueda por pasada.
- Por defecto es una pasada, se agregan más al hacer clic en el botón “+”.
- Cantidad de vecinos mínimos y máximos a utilizar.
- Cantidad de vecinos máximos por octante (0 significa que no usa este límite).
- Cantidad de vecinos máximos por sondaje (0 significa que no usa este límite).
- Valor máximo de las variables (Capping): cualquier valor superior se deja con este límite.
- Control de valores altos (High Yield): radios y ángulos para tratar valores sobre un límite.
- Bordes Suaves (Soft Boundaries): inclusión de datos entre geologías según los límites que se establecen.
Tanto el control de High Yield como Soft Boundaries no está disponible en la versión Demo.
[/et_pb_accordion_item][et_pb_accordion_item title=”UI: Variogramas”]
Variogramas
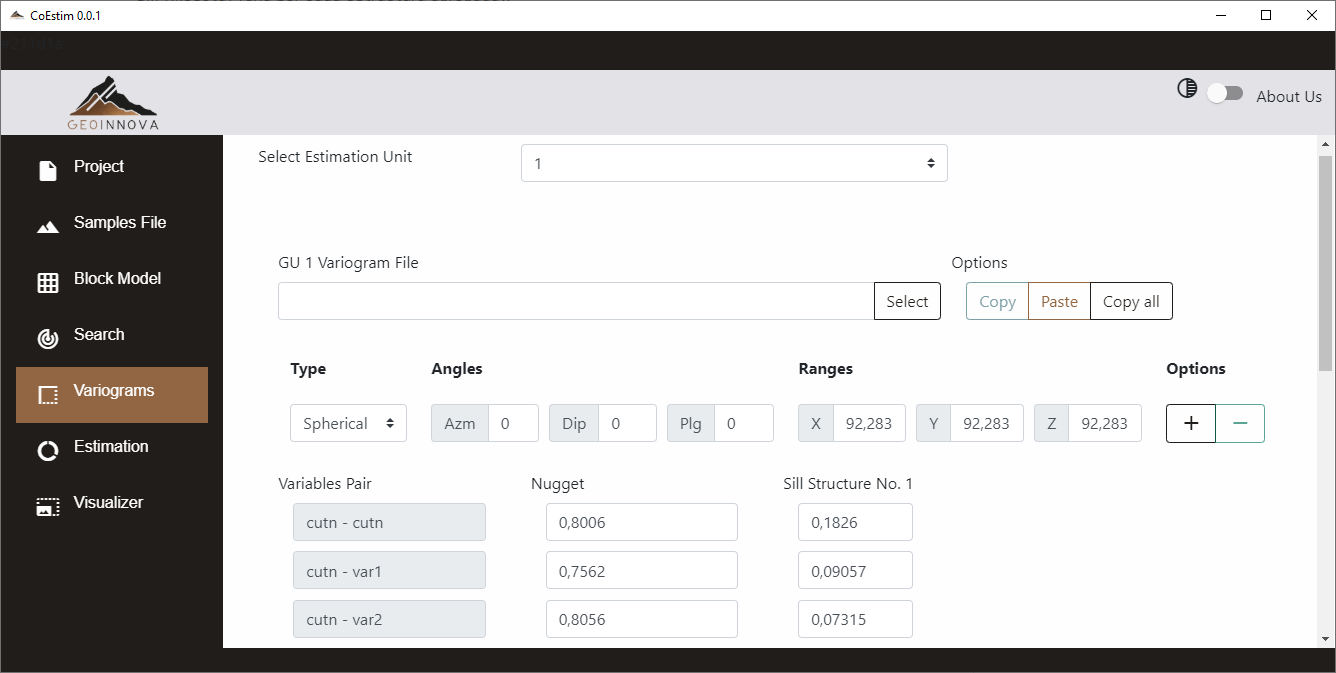
En este módulo del software se puede establecer los variogramas para las distintas unidades geológicas que son encontradas en el modelo de bloques. Si no se establecen las cabeceras para la geología en los archivos de datos y de modelo de bloques se genera una unidad por defecto que será aplicada para todos los bloques y datos.
En esta vista se puede seleccionar la unidad geológica y establecer el variograma asociado. Por defecto se muestra una estructura para ser completada y existe la opción de agregar más estructuras y de eliminar una de ellas.
Cada estructura tiene los siguientes datos:
- Tipo:
- Esférico
- Exponencial
- Cúbico
- Gaussiano
- Rangos:
- X,Y,Z
- Ángulos:
- Azimuth, Dip, Plunge
Además, por cada variable y par de variables se debe especificar:
- Nugget (efecto pepa).
- Sill (Meseta) (una por cada estructura agregada).
Cabe señalar que los datos ingresados en los campos de “Nugget” luego formarán una matriz que debe ser definida positiva para que el algoritmo se ejecute correctamente.
Además, si se tiene los variogramas definidos en un archivo. var (Variotron), éstos pueden ser cargados seleccionando el archivo de variograma.
[/et_pb_accordion_item][et_pb_accordion_item title=”UI: Estimación”]
Estimación
En este módulo se debe establecer el archivo de salida de la estimación. El proceso genera un archivo de valores separados por comas (.csv) que corresponde al modelo de bloques cargado en el software con las columnas de valores estimados y su varianza para cada una de las variables seleccionadas.
En esta sección también se puede generar un archivo de parámetros para utilizar CoEstim por línea de comandos, pero no está disponible en esta versión.
Finalmente, luego de establecer todos los parámetros necesarios, se puede ejecutar la estimación con el botón “Run Cokrige”.

Durante la ejecución de la co-estimación, la interfaz quedará bloqueada y se mostrarán barras de avance de la estimación. Cuando finalice correctamente, en la interfaz se muestra un mensaje de finalización de color verde. Si ocurre algún problema se mostrará un mensaje de error en color rojo.
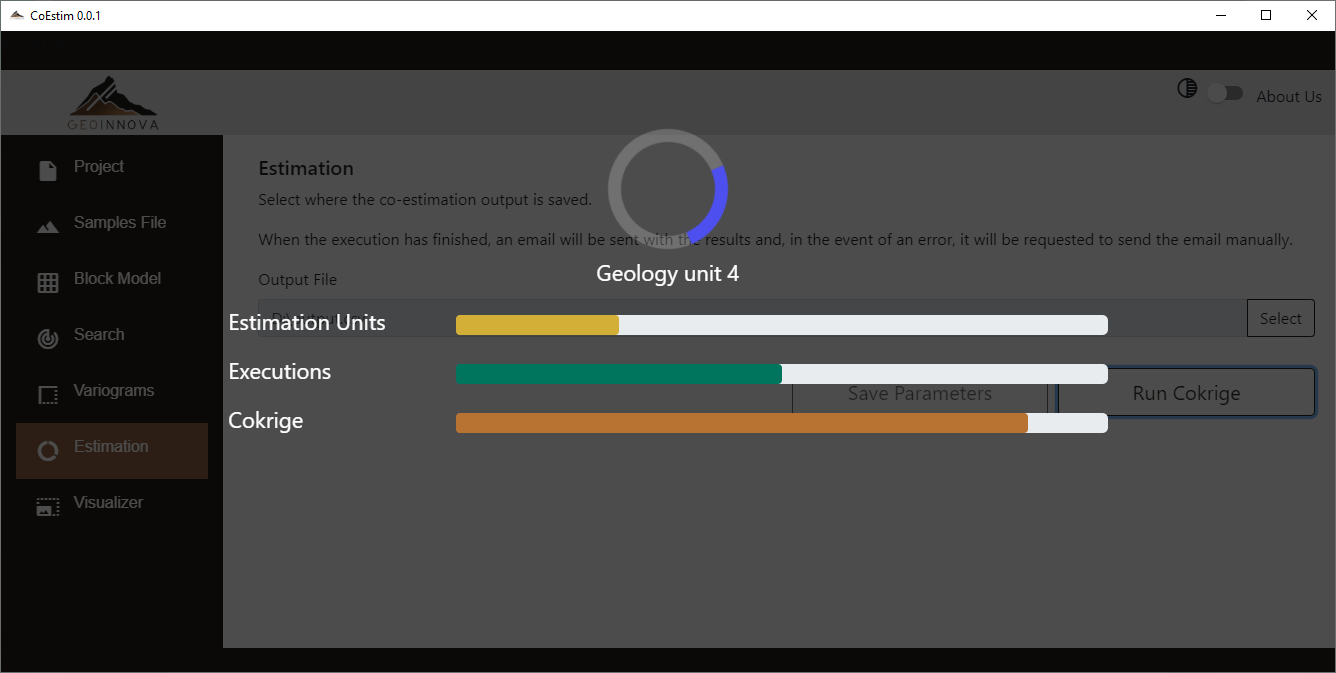
Luego de una ejecución correcta se puede acceder al archivo que estableció como salida para ser utilizado como estime conveniente el usuario.
[/et_pb_accordion_item][et_pb_accordion_item title=”UI: Visualizador 3D”]
Visualizador
En este módulo se puede acceder a la visualización de los resultados de la estimación. La interfaz muestra los controles de la ventana de visualización para que el usuario pueda moverse dentro del mismo. En la parte inferior el usuario debe seleccionar lo que desea visualizar, tanto de la base de datos como del modelo de bloques. De ambos archivos sólo se pueden seleccionar las variables utilizadas en la co-estimación y la geología.
En la selección de variable a visualizar se debe advertir que ambos deben ser del mismo tipo, esto es, ambos deben ser variables categóricas o continuas. El visualizador no se desplegará si no se cumple esta condición.
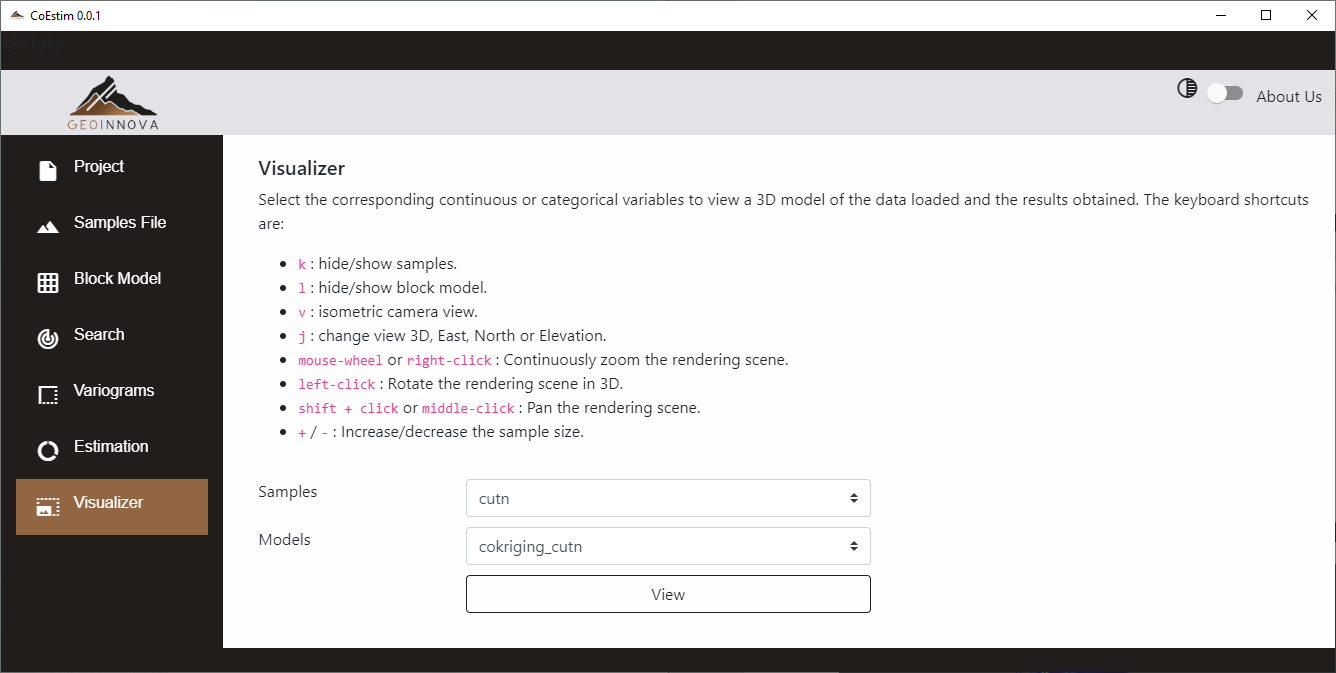
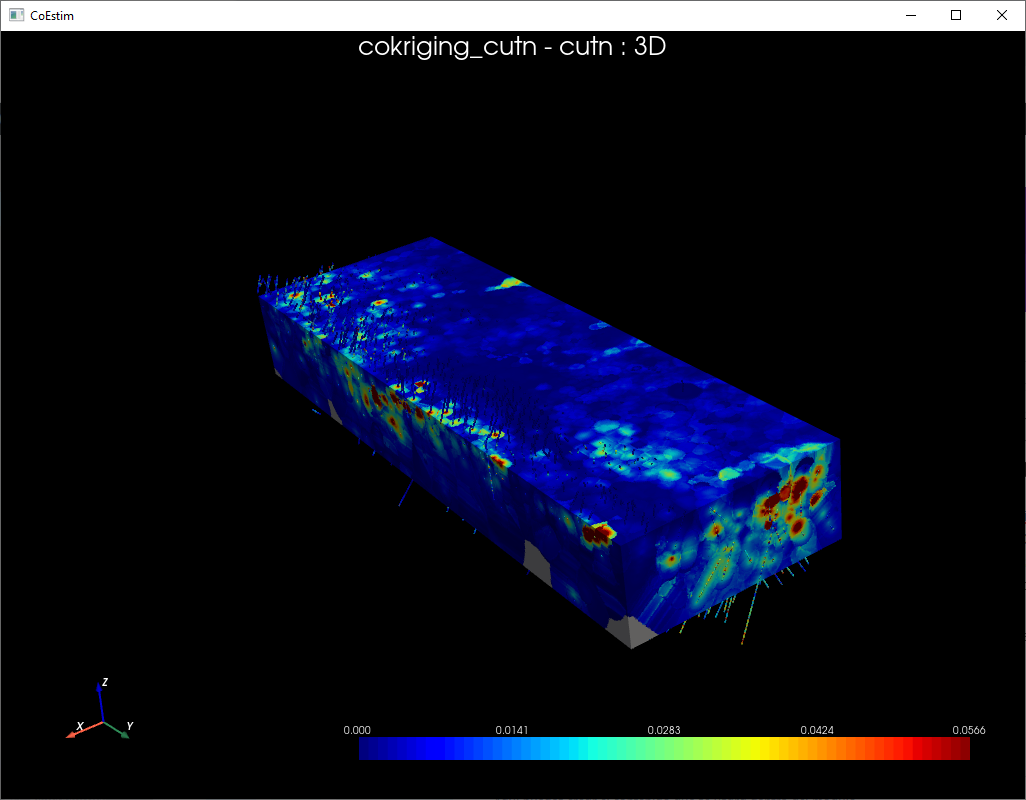
Luego de seleccionar las variables a visualizar, se debe hacer clic en el botón “View”. Esto desplegará una ventana donde se mostrarán el modelo de bloques y la base de datos (muestras, sondajes) en una vista 3D. Dentro de esta ventana el usuario podrá utilizar los comandos listados en la vista de CoEstim mencionada anteriormente. En las vistas de cortes se puede utilizar el “slider” de color naranjo ubicado en la parte derecha de la ventana para que el usuario se mueva dentro del volumen de los datos.
El usuario podrá tener la cantidad de ventanas de visualización que estime conveniente y mientras el rendimiento de su hardware lo permita.
[/et_pb_accordion_item][et_pb_accordion_item title=”Demo Version”]
Versión Demo
Qué Buscamos
La motivación de entregar de versión al público es principalmente para poner a prueba nuestros algoritmos y su rendimiento en diferentes configuraciones de hardware, principalmente en diferentes tarjetas de video (GPU). Los casos creados se basan en el trabajo de nuestros consultores que todos los días deben realizar estimaciones de recursos, y tanto el volumen de datos y de bloques como los parámetros de estimación están dentro de los rangos normales de trabajo.
Como la versión Demo está enfocada en medir el rendimiento de los procesos en diferentes configuraciones de hardware, los casos a ejecutar están restringidos en todas sus configuraciones exceptuando el caso “custom” donde podrá modificar la configuración de los archivos de datos y modelo de bloques, además de los parámetros de búsqueda y variogramas. Además, si se prefiere también es posible utilizar sus propios modelos de bloques y archivos de datos (en formato csv) para su posterior estimación, siempre y cuando el modelo de bloque no exceda los 1000 bloques o puntos.
Casos
Caso 1
Consiste en una estimación de leyes de CuT en un modelo de 10M de bloques de manera global (sin UG), para demostrar los bajos tiempos que logra el CoEstim.
- Modelo de Bloques: 10.440.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 1
- Geología: Sin geología (UG global).
- Número de pasadas: 2
- Radios por pasada:
- X: 50; Y: 50; Z: 50
- X: 150; Y: 150; Z: 150
- Ángulos:
- Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Simple.
- Media Global:
- Variable 1: 0.0
- Valores por defecto:
- Unidad Geológica Global: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
Caso 2
Consiste en estimaciones de leyes de CuT y otras 4 generadas a partir de la primera de manera global en un depósito. El CuT es la variable mejor muestreada, mientras que las otras están submuestreados. Las relaciones existentes entre estas variables permiten coestimar en zonas con poca información.
- Modelo de Bloques: 870.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 5
- Geología: Sin geología (UG global).
- Número de pasadas: 2
- Radios por pasada:
- X: 30; Y: 30; Z: 30
- X: 75; Y: 75; Z: 75
- Ángulos:
- Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Ordinario.
- Valores por defecto:
- Unidad Geológica Global: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
Caso 3
Consiste en una estimación de leyes de CuT en un modelo de 10M de bloques en 4 UG’s, para demostrar los bajos tiempos que logra el CoEstim.
- Modelo de Bloques: 10.440.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 1
- Geología: 4 unidades geológicas.
- Número de pasadas: 2
- Radios por pasada:
- X: 35; Y: 35; Z: 35
- X: 75; Y: 75; Z: 75
- Ángulos: Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Simple.
- Media Global:
- Variable 1: 0.0
- Valores por defecto:
- UG 1: -99
- UG 2: -99
- UG 3: -99
- UG 4: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
Caso 4
Consiste en estimaciones de leyes de CuT y otras 4 leyes generadas a partir de la primera pertenecientes a un depósito, como en el caso 2, pero por unidades geológicas.
- Modelo de Bloques: 870.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 5
- Geología: 4 unidades geológicas.
- Número de pasadas: 2
- Radios por pasada:
- X: 50; Y: 50; Z: 50
- X: 100; Y: 100; Z: 100
- Ángulos: Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Ordinario.
- Valores por defecto:
- UG 1: -99
- UG 2: -99
- UG 3: -99
- UG 4: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
Caso Custom:
- Modelo de Bloques: 870.000 bloques.
- Base de Datos: 153.772 muestras.
[/et_pb_accordion_item][et_pb_accordion_item title=”Recolección de Datos y Licenciamiento”]
Recolección de Datos
Esta versión de CoEstim recopila automáticamente datos de las ejecuciones de los casos previamente descritos, esto a través de envío del log de ejecución por correo.
Además, al final de cada ejecución tienes la opción de enviar tus datos para inscribirte en el sorteo de un iPad 10.2″ 32GB, y para acceder a la versión full de CoEstim y otras de nuestras herramientas.
La información recolectada de las ejecuciones es principalmente de la configuración de los datos y modelo de bloques, los parámetros de búsqueda y variogramas. La única información del usuario que se recopila es la ingresada de manera opcional en el formulario al final de cada ejecución, la tarjeta de video que posee el computador donde se está ejecutando y parámetros asociados a la ejecución sobre el dispositivo. No se recopila información adicional. La información enviada a través del formulario de inscripción será utilizada solamente para efectos de contacto, para entregar la versión full de CoEstim y otras de nuestras herramientas, y para el sorteo del iPad Mini.
Licenciamiento
Este software puede distribuirse de manera gratuita y ejecutar los casos entregados junto con el ejecutable.
No puede ser editado o utilizado para otra tarea diferente a las presentadas en este artículo.
La caducidad de la licencia es el 31 de diciembre de 2020.
[/et_pb_accordion_item]
[/et_pb_accordion][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Coestimacion” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
CoEstimación
El cokriging es la extensión multivariable del kriging y se utiliza principalmente con 2 objetivos: cuando existe una variable A, submuestreada, correlacionada con una variable B, más muestreada (heterotopía), y se busca explotar esta relación para estimar en zonas con poca información de la variable A, o cuando se tienen dos o más variables correlacionadas y se desea conservar en cierta medida esta relación.
El cokriging implementado asume un modelo lineal de corregionalización para el modelamiento conjunto de los variogramas simples y cruzados.
Si dos variables están correlacionadas y son estimadas por kriging de manera independiente, es decir, parámetros de búsquedas y variogramas distintos, no se asegura que la relación entre las variables se conserve.
Cokriging tiene muchísimas aplicaciones en geología, geofísica y geometalurgia, en donde test baratos masivos tales como ICP, NIR o mapeos pueden ser combinados con test metalúrgicos escasos y caros, para coestimar y predecir el comportamiento de porcentaje de mineralogías, recuperaciones, variables de conminución, velocidades de sedimentación, yield stress, entre muchas otras. Un ejemplo es el que se muestra a continuación, donde para estimar calcopirita en un depósito existen unas pocas muestras con análisis qemscan, mientras que la información asociada a mapeos de mineralogía es mucho más densa.
Actualmente esta metodología de estimación no está altamente difundida en la industria minera por la falta de softwares que incorporen este método, los que en general presentan tiempos de ejecución altos.
Buscamos ayudar a familiarizar a la industria con este tipo de técnicas multivariables muy útiles en el contexto de geociencias, junto con enfrentar los tiempos de cálculos asociados a los sistemas multivariables.
Considerando estas condiciones y sus múltiples aplicaciones es que decidimos aventurarnos con cokriging.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”CoEstimIntro” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
CoEstim
CoEstim es un software creado por el Centro de I+D de GeoInnova con el apoyo de Corfo. Su motivación principal es la creación de una herramienta de coestimación que saque el máximo provecho al hardware donde es ejecutado, en especial a la tarjeta de procesamiento gráfico que contenga (GPU en sus siglas en inglés).
Características principales de Coestim:
- Lectura y escritura de archivos .csv.
- Estimación multivariable bajo modelo LMC.
- Cokriging ordinario y simple con media global o local.
- Adaptado para manejo de bases de datos heterotópicas (distinto N por cada variable).
- Acepta estimaciones de varias unidades de estimación simultáneamente.
- Incorpora estimaciones sucesivas de radios incrementales (pasadas).
- Restricciones aseguramiento de interpolación muestras por sondajes y octantes.
- Capping y trimming limits.
- Valor por defecto por unidad para bloques no estimados.
- Permite compartir muestras entre unidades.
- Estimación en nodos o bloques. Se puede cargar grilla parcial o completa.
- Incorpora visualizador 3D para verificación de resultados.
Para el modelamiento variográfico, el centro de I+D próximamente liberara un software de cálculo de variogramas y ajuste semiautomático basado en Optimización por enjambre de partículas usando computo por GPU (Variograma).
Cimientos
El algoritmo base de CoEstim fue obtenido del programa KT3D y las librerías adicionales de GSLIB, sin embargo, ciertos procesos de este algoritmo fueron optimizados y otros fueron completamente reemplazados.
La convención que mantiene CoEstim de GSLIB es la definición de sus ángulos, esto es, se considera el eje Y como eje principal y los ángulos de Euler rotan en torno a los ejes ZXY. Esta convención se utiliza en los ángulos de búsqueda de muestras cercanas (búsqueda global o local) y en los ángulos de las estructuras de los variogramas.
Optimizaciones
Como mencionamos anteriormente, el algoritmo base fue optimizado para lograr un mejor rendimiento. Una de las optimizaciones más fuertes incorporadas fue la implementación del corazón de la estimación (búsqueda de vecinos, matriz de covarianza y su resolución) sobre GPU. Esta implementación bajó fuertemente los tiempos de ejecución del algoritmo llegando a ser hasta 10 veces más rápido que otros softwares comerciales sobre depósitos medianos, y hasta 5 veces más rápido sobre depósitos de gran tamaño.
Otra optimización se realizó sobre la estructura para el ordenamiento. GSLIB utiliza “Super Block Search” para ordenar tanto el modelo de bloques y la base de datos, para luego sobre ella realizar la búsqueda de muestras cercanas de cada bloque iterando por cada uno de ellos. Nuestra optimización se da durante la creación de esta estructura y su utilización en generar paquetes de bloques a estimar que son enviados a la GPU para estimar más de un bloque a la vez.
También se utilizaron algoritmos de ordenamiento óptimos y estructuras de datos para realizar tareas auxiliares a la estimación y que aceleraron el proceso.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”CoEstimUI_intro” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
User Interface
CoEstim primero nace como un programa ejecutable por línea de comandos, pero el Centro de I+D de GeoInnova se ha dedicado a generar una interfaz para la utilización de CoEstim de manera más amigable con el usuario.
Esta interfaz se divide en las partes necesarias para llevar a cabo la coestimación: definición del modelo de bloques, definición de la base de datos, definición de parámetros de búsqueda y definición de variogramas (global o por unidad de estimación).
Cabe señalar que los archivos soportados por CoEstim consisten en modelos de bloques y bases de datos .csv con formato de coordenadas X,Y,Z más las columnas con las variables de interés.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Base de Datos” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Base de datos
En este módulo se puede seleccionar el archivo que será utilizado como base de datos. Se debe seleccionar con el botón “Select”. Al elegir un archivo en el cuadro de diálogo, se procede a cargar sus cabeceras. Para agregar los tipos de columnas necesarios, se debe hacer clic en “Add Column”, que desplegará una ventana donde se listan las cabeceras del archivo.
Por cada cabecera se despliegan tipos que se requieren: X, Y, Z, ID de sondaje (Drillhole ID), Geología (Estimation Unit), y variables (Estimation Variable). Es obligatorio establecer las cabeceras para X, Y, Z, así como al menos escoger una cabecera como variable. Las cabeceras para el ID de los sondajes y la Geología no es necesario establecerlas, pero se debe considerar que: si no se establece el ID de sondajes, no se puede hacer filtro por sondaje en la búsqueda; si no se establece Geología (Estimation Unit) en la base de datos, tampoco podrá hacerlo en el modelo de bloques y se considerará una sola unidad de estimación para todos los bloques y todas las muestras.
Una vez seleccionadas las cabeceras y haciendo clic en “Confirm”, la vista principal muestra las cabeceras seleccionadas con su respectivo tipo. Para las cabeceras del tipo “Estimation Variable” se muestra además los campos para establecer los límites de corte en los valores de esas variables.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Modelo de Bloques ” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Modelo de Bloques
Este módulo permite cargar el archivo de modelo de bloques que será co-estimado. Al igual que en el módulo anterior, luego de cargadas las cabeceras del archivo, se deben agregar columnas con el botón “Add Column” y seleccionar los tipos de cabecera necesarios, en este caso X, Y, Z y Geología (Estimation Unit), siendo las primeras tres obligatorias y la Geología opcional, cumpliendo las mismas condiciones antes mencionadas si no se establece.
También se pueden establecer tipos de cabecera adicionales: X Radius, Y Radius, Z Radius, Azimuth, Dip y Plunge. Estos son utilizados para la búsqueda local. También se puede definir una media local (Local Mean) para ser utilizada en la ejecución de Cokrige Simple. Estos tipos de cabecera adicionales no están disponibles para ser seleccionadas en la versión de prueba.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Parámetros de Búsqueda ” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Parámetros de Búsqueda
Este módulo contiene todos los parámetros relacionados con la búsqueda de la vecindad de datos de los bloques para realizar la co–estimación.
En esta interfaz podemos configurar:
- Tipo de Cokrige:
- Medias globales de las variables.
- Valores por defecto de las variables (en caso de no estimar en el bloque).
- Tipo de estimación:
- Puntual: se debe establecer la discretización de los bloques.
- Block: se debe establecer el tamaño de los bloques.
- Ángulos de la búsqueda.
- Radios de búsqueda por pasada.
- Por defecto es una pasada, se agregan más al hacer clic en el botón “+”.
- Cantidad de vecinos mínimos y máximos a utilizar.
- Cantidad de vecinos máximos por octante (0 significa que no usa este límite).
- Cantidad de vecinos máximos por sondaje (0 significa que no usa este límite).
- Valor máximo de las variables (Capping): cualquier valor superior se deja con este límite.
- Control de valores altos (High Yield): radios y ángulos para tratar valores sobre un límite.
- Bordes Suaves (Soft Boundaries): inclusión de datos entre geologías según los límites que se establecen.
Tanto el control de High Yield como Soft Boundaries no está disponible en la versión Demo.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Variogramas” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Variogramas
En este módulo del software se puede establecer los variogramas para las distintas unidades geológicas que son encontradas en el modelo de bloques. Si no se establecen las cabeceras para la geología en los archivos de datos y de modelo de bloques se genera una unidad por defecto que será aplicada para todos los bloques y datos.
En esta vista se puede seleccionar la unidad geológica y establecer el variograma asociado. Por defecto se muestra una estructura para ser completada y existe la opción de agregar más estructuras y de eliminar una de ellas.
Cada estructura tiene los siguientes datos:
- Tipo:
- Esférico
- Exponencial
- Cúbico
- Gaussiano
- Rangos:
- X,Y,Z
- Ángulos:
- Azimuth, Dip, Plunge
Además, por cada variable y par de variables se debe especificar:
- Nugget (efecto pepa).
- Sill (Meseta) (una por cada estructura agregada).
Cabe señalar que los datos ingresados en los campos de “Nugget” luego formarán una matriz que debe ser definida positiva para que el algoritmo se ejecute correctamente.
Además, si se tiene los variogramas definidos en un archivo. var (Variotron), éstos pueden ser cargados seleccionando el archivo de variograma.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Estimación ” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Estimación
En este módulo se debe establecer el archivo de salida de la estimación. El proceso genera un archivo de valores separados por comas (.csv) que corresponde al modelo de bloques cargado en el software con las columnas de valores estimados y su varianza para cada una de las variables seleccionadas.
En esta sección también se puede generar un archivo de parámetros para utilizar CoEstim por línea de comandos, pero no está disponible en esta versión.
Finalmente, luego de establecer todos los parámetros necesarios, se puede ejecutar la estimación con el botón “Run Cokrige”.
Durante la ejecución de la co-estimación, la interfaz quedará bloqueada y se mostrarán barras de avance de la estimación. Cuando finalice correctamente, en la interfaz se muestra un mensaje de finalización de color verde. Si ocurre algún problema se mostrará un mensaje de error en color rojo.
Luego de una ejecución correcta se puede acceder al archivo que estableció como salida para ser utilizado como estime conveniente el usuario.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Visualizador” background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Visualizador
En este módulo se puede acceder a la visualización de los resultados de la estimación. La interfaz muestra los controles de la ventana de visualización para que el usuario pueda moverse dentro del mismo. En la parte inferior el usuario debe seleccionar lo que desea visualizar, tanto de la base de datos como del modelo de bloques. De ambos archivos sólo se pueden seleccionar las variables utilizadas en la co-estimación y la geología.
En la selección de variable a visualizar se debe advertir que ambos deben ser del mismo tipo, esto es, ambos deben ser variables categóricas o continuas. El visualizador no se desplegará si no se cumple esta condición.
Luego de seleccionar las variables a visualizar, se debe hacer clic en el botón “View”. Esto desplegará una ventana donde se mostrarán el modelo de bloques y la base de datos (muestras, sondajes) en una vista 3D. Dentro de esta ventana el usuario podrá utilizar los comandos listados en la vista de CoEstim mencionada anteriormente. En las vistas de cortes se puede utilizar el “slider” de color naranjo ubicado en la parte derecha de la ventana para que el usuario se mueva dentro del volumen de los datos.
El usuario podrá tener la cantidad de ventanas de visualización que estime conveniente y mientras el rendimiento de su hardware lo permita.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Versión Demo 1″ background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid”]
Versión Demo
Qué Buscamos
La motivación de entregar de versión al público es principalmente para poner a prueba nuestros algoritmos y su rendimiento en diferentes configuraciones de hardware, principalmente en diferentes tarjetas de video (GPU). Los casos creados se basan en el trabajo de nuestros consultores que todos los días deben realizar estimaciones de recursos, y tanto el volumen de datos y de bloques como los parámetros de estimación están dentro de los rangos normales de trabajo.
Como la versión Demo está enfocada en medir el rendimiento de los procesos en diferentes configuraciones de hardware, los casos a ejecutar están restringidos en todas sus configuraciones exceptuando el caso “custom” donde podrá modificar la configuración de los archivos de datos y modelo de bloques, además de los parámetros de búsqueda y variogramas. Además, si se prefiere también es posible utilizar sus propios modelos de bloques y archivos de datos (en formato csv) para su posterior estimación, siempre y cuando el modelo de bloque no exceda los 1000 bloques o puntos.
Casos
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” parallax_2=”off” parallax_method_2=”off” column_padding_mobile=”on”][et_pb_column type=”1_2″][et_pb_text admin_label=”Caso 1 2″ background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Caso 1
Consiste en una estimación de leyes de CuT en un modelo de 10M de bloques de manera global (sin UG), para demostrar los bajos tiempos que logra el CoEstim.
- Modelo de Bloques: 10.440.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 1
- Geología: Sin geología (UG global).
- Número de pasadas: 2
- Radios por pasada:
- X: 50; Y: 50; Z: 50
- X: 150; Y: 150; Z: 150
- Ángulos:
- Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Simple.
- Media Global:
- Variable 1: 0.0
- Valores por defecto:
- Unidad Geológica Global: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
Caso 2
Consiste en estimaciones de leyes de CuT y otras 4 generadas a partir de la primera de manera global en un depósito. El CuT es la variable mejor muestreada, mientras que las otras están submuestreados. Las relaciones existentes entre estas variables permiten coestimar en zonas con poca información.
- Modelo de Bloques: 870.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 5
- Geología: Sin geología (UG global).
- Número de pasadas: 2
- Radios por pasada:
- X: 30; Y: 30; Z: 30
- X: 75; Y: 75; Z: 75
- Ángulos:
- Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Ordinario.
- Valores por defecto:
- Unidad Geológica Global: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
[/et_pb_text][/et_pb_column][et_pb_column type=”1_2″][et_pb_text admin_label=”Caso 3 4″ background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Caso 3
Consiste en una estimación de leyes de CuT en un modelo de 10M de bloques en 4 UG’s, para demostrar los bajos tiempos que logra el CoEstim.
- Modelo de Bloques: 10.440.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 1
- Geología: 4 unidades geológicas.
- Número de pasadas: 2
- Radios por pasada:
- X: 35; Y: 35; Z: 35
- X: 75; Y: 75; Z: 75
- Ángulos: Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Simple.
- Media Global:
- Variable 1: 0.0
- Valores por defecto:
- UG 1: -99
- UG 2: -99
- UG 3: -99
- UG 4: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
Caso 4
Consiste en estimaciones de leyes de CuT y otras 4 leyes generadas a partir de la primera pertenecientes a un depósito, como en el caso 2, pero por unidades geológicas.
- Modelo de Bloques: 870.000 bloques.
- Base de Datos: 153.772 muestras.
- Número de variables: 5
- Geología: 4 unidades geológicas.
- Número de pasadas: 2
- Radios por pasada:
- X: 50; Y: 50; Z: 50
- X: 100; Y: 100; Z: 100
- Ángulos: Azimuth: 0; Dip: 0; Plunge: 0
- Mín. y Máx. de muestras: 4 y 16.
- Máx. de muestras por sondaje: 0 (no se usa).
- Máx. de muestras por octante: 0 (no se usa).
- Tipo de Kriging: Ordinario.
- Valores por defecto:
- UG 1: -99
- UG 2: -99
- UG 3: -99
- UG 4: -99
- Tipo de Estimación: Punctual
- Discretización: X: 1; Y: 1; Z: 1
- Valor máximo de variables: No se usa.
Caso Custom:
- Modelo de Bloques: 870.000 bloques.
- Base de Datos: 153.772 muestras.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label=”Fila” make_fullwidth=”off” use_custom_width=”off” width_unit=”on” use_custom_gutter=”off” padding_mobile=”off” disabled=”on” disabled_on=”on|on|on” allow_player_pause=”off” parallax=”off” parallax_method=”off” make_equal=”off” parallax_1=”off” parallax_method_1=”off” column_padding_mobile=”on”][et_pb_column type=”4_4″][et_pb_text admin_label=”Versión Demo 2″ background_layout=”light” text_orientation=”left” use_border_color=”off” border_color=”#ffffff” border_style=”solid” saved_tabs=”all”]
Descarga
Puedes descargar directamente el ejecutable y los proyectos AQUI.
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]