Una parte importante de las Ciencias de la Computación se relaciona con los algoritmos: su creación, implementación y optimización. Éstos pueden ir desde un proceso netamente humano como hacer una compra, hasta un proceso matemático para detección o diagnóstico de enfermedades automatizado.
Sea cual sea el origen, todos ellos incluyen la obtención de datos, el procesamiento de ellos, y la generación de resultados como consecuencia del proceso. A esto se le llama Algoritmo.
En la industria minera, los modelos predictivos espaciales y sus algoritmos asociados son parte integral del desarrollo de proyectos mineros y ciclo de producción, por medio de la caracterización de recursos geológicos, variables geometalúrgicas y cuantificación de la incertidumbre asociada para uso en planificación minera y valorización económica.
En GeoInnova creemos que el futuro de la caracterización espacial de variables geo-minera-metalúrgica, será un procesamiento en línea con adición de nueva información de distinta naturaleza y temporalidad, tales como análisis químicos en DH y BH, test metalúrgicos, imágenes, espectros, mapeos, para luego generar modelos espaciales y procesos de toma de decisión.
En este contexto, la optimización y el desarrollo de algoritmos que permitan avanzar en esta dirección es clave, por lo cual estamos trabajando en ello enfocándonos en entregar a nuestros clientes resultados más precisos y flexibles con tiempos de ejecución bajos.
Cómputo en Paralelo: Breve Introducción
Si bien el corazón de la optimización de algoritmos consiste en utilizar estructuras de datos, métodos de búsqueda, de orden o de cálculo que sean óptimos para el problema que se quiere abordar, la posibilidad de realizar cómputo en paralelo reduce los tiempos de ejecución de modo importante y aún más si un algoritmo es óptimo.
El cómputo en paralelo es la técnica que permite a varios procesos de un mismo programa ejecutarse simultáneamente aprovechando la disponibilidad de hilos de ejecución que poseen los procesadores (CPU). Esta capacidad de las unidades de procesamiento central se vio aumentada cuando comenzaron a fabricarse y comercializarse procesadores multi-núcleo, que permitían tener aún más hilos de procesamiento disponibles que los procesadores de un sólo núcleo.
Posteriormente, comenzaron a fabricarse unidades de procesamiento gráfico (GPU) multi-núcleo con capacidad de procesar no sólo video e imágenes, sino también grandes volúmenes de datos superando incluso a las unidades de procesamiento central (CPU).
En GeoInnova estamos al tanto de las capacidades de las GPU’s, el potencial que tienen para realizar cálculos y lo bien que se pueden ajustar a algoritmos geoestadísticos.
Cómputo en Paralelo: Los primeros pasos en GNV
Para GeoInnova el paralelismo no es nada nuevo. Desde el 2015 hemos realizado esfuerzos buscando las mejores herramientas tecnológicas disponibles para poder llevar a cabo la implementación de algoritmos paralelizados.
Como primer paso se seleccionó el framework CUDA de NVIDIA, por su potencial en esos años y, a modo de algoritmo de prueba, el cálculo experimental del variograma, el cual pese a su simplicidad es intensivo en cómputo debido a la cantidad de datos y variables. Esto último puede ser prohibitivo en escenarios de datos de pozos de tronadura, imágenes, imágenes Hiperespectrales y espectros.
Del primer aprendizaje de paralelización de la implementación del variograma en GPU con CUDA se rescató que, si bien el paralelismo es una buena herramienta para reducir tiempos de ejecución, el framework CUDA no es lo suficientemente flexible para abordar todas las problemáticas que surgirían en cálculos más complejos, así como también en la dificultad para generar código, además que este framework es exclusivo de NVIDIA [Pola et al, 2017].
Como resultado de esta primera aproximación se adoptó el framework OpenCL para implementar algoritmos paralelizados, ya que a diferencia de CUDA, se puede implementar sobre cualquier dispositivo de procesamiento de datos, sea CPU o GPU, y de los principales fabricantes de estos dispositivos: Intel, AMD y NVIDIA.
Cómputo en Paralelo: El desafío de la predicción espacial
Luego de los aprendizajes previos, el desafío fue generar implementaciones de los algoritmos de predicción espacial Kriging y Co-Kriging, que requieren una gran potencia de cálculo y que nos propusimos optimizar e implementar utilizando el cómputo en paralelo sobre GPU utilizando C++ y OpenCL.
Para evitar construir una implementación de laboratorio, parte del desafío fue generar implementaciones utilizables bajo las prácticas actuales de la industria minera tales como planes de kriging flexibles en términos de restricción de datos, valores extremos y uso de orientación, anisotropía variable en búsqueda de datos y variograma.
Kriging y Co-Kriging: CoEstim
El primer paso para implementar estos algoritmos sobre GPU es optimizarlos lo más posible antes de llegar a ese punto. El algoritmo base lo obtuvimos desde KT3D y de COKB3D GSLIB [Deutsch et al, 1992], adaptándolo para el caso multivariable (>10) y manejo de datos heterotópicos. La adaptación/ traducción fue realizada desde Fortran a C++. Luego, optimizamos cada una de sus partes hasta llegar a un punto donde no podíamos obtener los mismos resultados con un menor tiempo de ejecución.
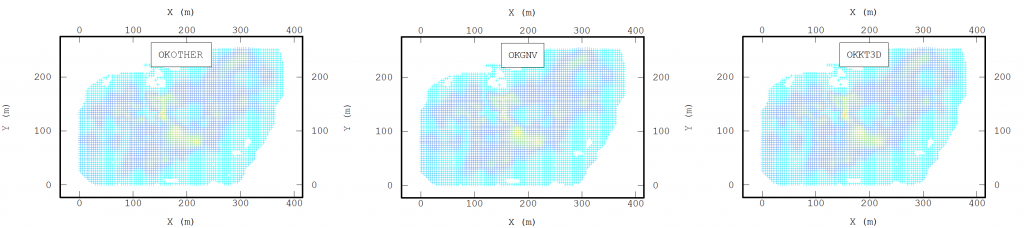
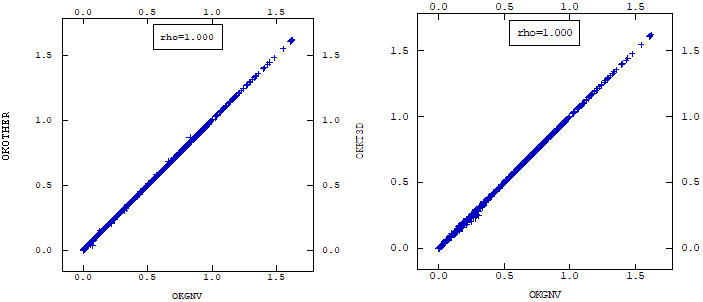
Al paralelizar el algoritmo, se revisitó el algoritmo para definir qué partes de éste serían paralelizadas y aplicamos dos criterios: el proceso más lento y la independencia entre cálculos. Este último criterio es debido a que, para evitar cuellos de botella en el paralelismo, todos los hilos de ejecución deben estar independientes entre ellos para así aprovechar al máximo la capacidad de procesamiento. Así concluimos que los procesos a paralelizar serían: la búsqueda de vecinos, el cálculo de la matriz de covarianza y su reducción para cada punto a estimar.
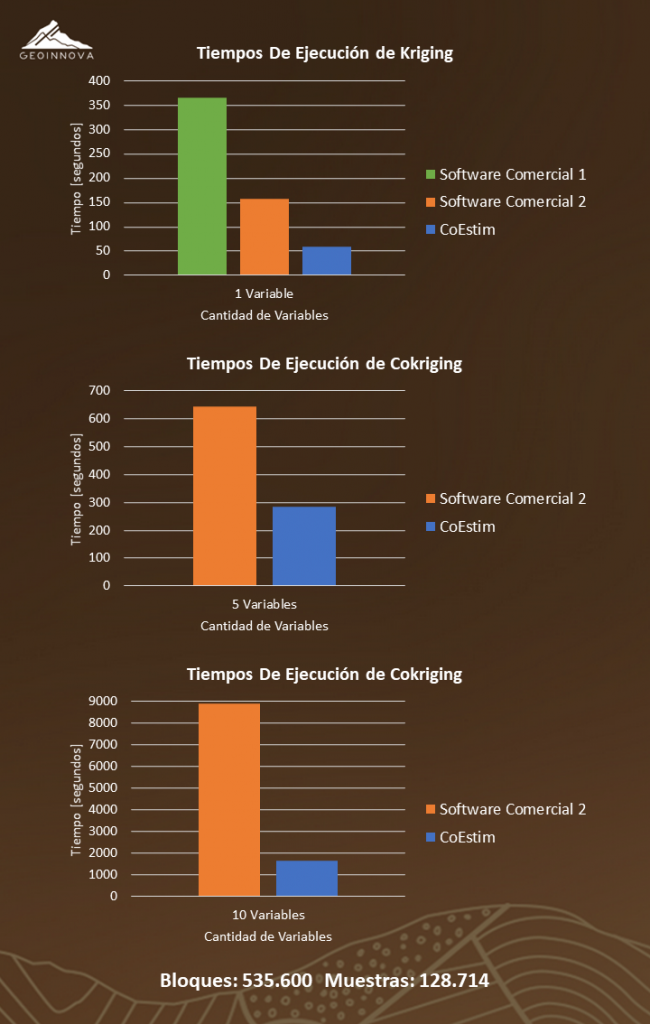
Luego de la definición de los procesos a ejecutar y su diseño, se procedió a implementar los subprogramas necesarios para utilizar sobre la GPU. Al obtener versiones estables procedimos a comparar tiempos de ejecución, y los resultados fueron sorprendentes. A continuación, presentamos los tiempos de ejecución de CoEstim y otros dos softwares comerciales.
Simulación de variables continuas: CoSim
El segundo desafío corresponde a modelos estocásticos espaciales de variables continuas tales como leyes de cobre, contaminantes y variables geo-metalúrgicas. Los algoritmos asociados a estos son más demandantes en cómputo y en manejo de grandes cantidades de información que los algoritmos antes presentados.
El primer paso fue la evaluación de selección del marco del modelo y algoritmo. Seleccionamos el marco multigaussiano por su penetración en la industria y adecuación a la gran mayoría de los depósitos y variables con que nos enfrentamos día a día.
Como algoritmo de simulación se evaluó el algoritmo SGSIM de simulación secuencial gaussiana disponible como código fuente en la GSLIB [Deutsch et al, 1992] en Fortran como primera opción, pero terminamos escogiendo el algoritmo de simulación TBCOSIM disponible en Matlab en la publicación del 2008 del profesor Xavier Emery de la Universidad de Chile [Emery et al, 2008].
La razón de la selección del algoritmo de bandas rotantes es la flexibilidad que presenta en el caso multivariable y el potencial de paralelización al utilizar el método de bandas rotantes para generar los valores simulados no condicionales y co-kriging para condicionamiento por el método de substitución de los residuos, permitiéndonos reutilizar la implementación CoEstim previamente desarrollada.
Una vez optimizado el algoritmo y generada la versión paralelizada en GPU, lo bautizamos como CoSim.
Si bien los resultados eran interesantes en casos de pequeña-mediana escala, con grandes volúmenes de nodos a simular la capacidad de memoria de las GPU de las máquinas locales no era suficiente. Debido al volumen de memoria requerida y volumen de información generada, nos vimos en la necesidad de movernos a una solución de cómputo distribuido, en un principio en un clúster de computadores local y luego con distribución en la nube.
¡¡No es suficiente!!: Sistemas Distribuidos
Una vez obtenido un programa base paralelizado sobre GPU nos pusimos más ambiciosos aún y quisimos ir más lejos.
¿De qué otra manera podemos reducir aún más el tiempo de ejecución?
En el mundo de la computación el dicho “divide y vencerás” se utiliza mucho, sobre todo al momento de resolver problemas. Este se refiere a que un proceso complejo se puede ir dividiendo en subprocesos menos complejos y más abordables que el proceso original, y que la suma de estas partes dan el resultado esperado. También se aplica cuando múltiples máquinas realizan el mismo proceso y un problema se divide en partes iguales, una para cada máquina, llegando a un resultado en un menor costo de tiempo.
En los Sistemas Distribuidos se aplica esta premisa para diferentes fines: dividir un proceso en diferentes máquinas, cada una de ellas especializada en su tarea; generar sistemas de respaldos de datos con alta redundancia; generar sistemas de archivos compartidos editables por múltiples usuarios; para acelerar un proceso, entre otros. Para nuestro problema implementamos un sistema distribuido para bajar el tiempo de ejecución de tareas muy costosas, una de ellas es la Simulación de variables continuas.
Una vez generado el clúster, insertamos CoSim en ellos, y programamos el servidor para que hiciera la división del trabajo. Las máquinas utilizadas fueron computadores que estaban disponibles en las oficinas de GeoInnova. El resultado inicial fue un poco desalentador: Si bien nos permitió manejar grandes volúmenes de datos, las máquinas eran muy dispares en cuanto a potencia, unas demoraban demasiado y otras muy poco. La puesta en marcha era compleja y el tiempo de ejecución no bajó al nivel que esperábamos.
¿Cómo generar una cantidad de máquinas de iguales cualidades? Respuesta: Máquinas Virtuales. Pero ¿de dónde sacamos tanta potencia y cantidad? Respuesta: Google Cloud Compute Engine.
Distribución en la Nube
Para resolver el problema de homogenizar las máquinas donde se ejecuta CoSim recurrimos a la plataforma Compute Engine de Google Cloud. Esta plataforma nos permite generar máquinas virtuales donde podemos elegir sus características de muchas de las opciones que se ofrecen, además de contar con GPU disponible para ellas.
Trasladamos nuestro clúster a Compute Engine, donde utilizamos ocho máquinas virtuales como ejecutores y una como servidor. De esta manera obtuvimos los resultados que esperábamos, y más. Los tiempos de ejecución a continuación:
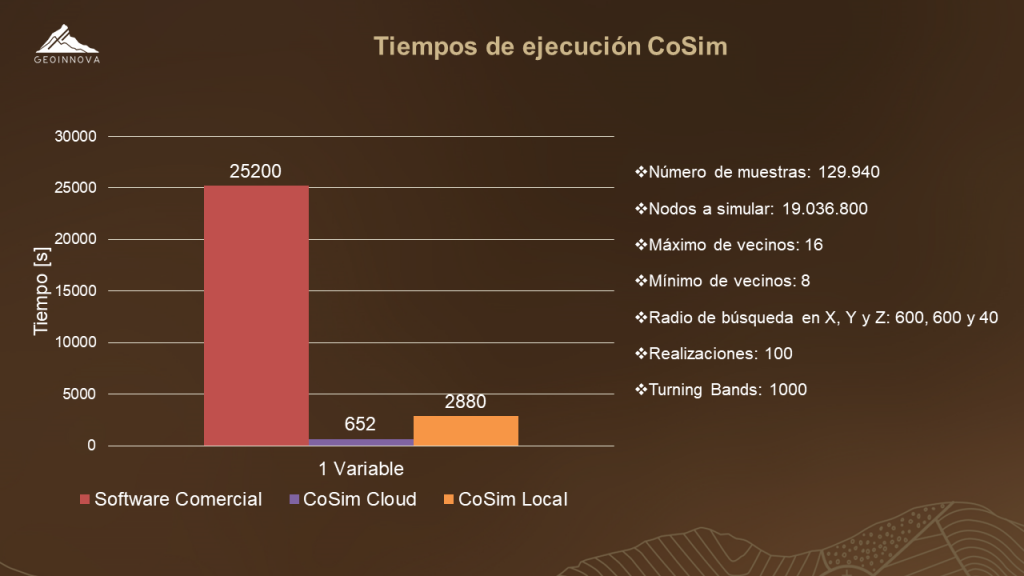
Al comparar la implementación Cosim-Local vs Cosim-Cloud nos dieron tiempos de ejecución hasta 10 veces menores en la versión Cloud, esto debido a la homogenización de las máquinas y que ellas tenían una GPU de gran potencia. Al comparar con el software comercial la bajada de tiempo es mucho más notoria para ambas versiones de CoSim.
Como hemos presentado, la paralelización de los procesos representa una mejora importante en el tiempo de ejecución, llegando a ser en ciertos casos hasta 10 veces más rápido que los softwares comerciales. Naturalmente las versiones de software comercial al no tener la misma implementación sobre GPU que los casos paralelizados sus tiempos son mayores y la comparación no es de algoritmo sino de implementación.
La distribución de procesos también permite una mejora en el tiempo de ejecución, sobre todo cuando se cuenta con máquinas de similares características y de alta potencia de cálculo, que fue lo que logramos en la versión Cloud de CoSim. Nuevamente los tiempos de las versiones de software comercial, al no tener la misma implementación paralelizada y distribuida, son ostensiblemente mayores, y ahora la comparación además de ser de implementación, también es de hardware.
Aplicaciones reales
Una de las ventajas de contar con el equipo de consultoría como contraparte del equipo de I+D, es la posibilidad de testeo continuo de CoEstim y CoSim en el contexto de ejecución de proyectos de modo paralelo a las metodologías tradicionales disponibles en los softwares comerciales. Esto ayudó a depurar, verificar y mejorar ambas aplicaciones durante los últimos dos años, permitiéndonos, por ejemplo, co-simular 3 variables en 21 millones de nodos con 100 realizaciones en tan solo 1 hora.
Aprendizajes y oportunidades
El cómputo paralelizado en GPU o distribuido en diversas máquinas permite disminuir los tiempos de cómputo de los algoritmos asociados a las problemáticas actuales de modelamiento geo-minero-metalúrgico, pero mucho más importante es que abre nuevas posibilidades de modelamiento con implicancias en la gestión del negocio minero, por ejemplo, cambiando potencialmente los ciclos de modelamiento-planificación por etapas, a un continuo.
Agradecimientos
Agradecemos al Centro de Innovación y Desarrollo SR-181 de GeoInnova, acreditado por Corfo, y al equipo de Consultoría involucrado en los temas de desarrollo de CoEstim, CoSim y cómputo distribuido, así como los proyectos Corfo 17ITE1-83672, 16GPI-60687, 15ITE1-48211.
Equipo Actual:
Alan Toledo  , Alejandro Cáceres , Manuel Hoffhein , Javier Ortiz , Cristóbal Barrientos .
, Alejandro Cáceres , Manuel Hoffhein , Javier Ortiz , Cristóbal Barrientos .
Participantes históricos I+D:
Daniel Pola , David Valenzuela , Sebastián Blasco .
Equipo de Consultoría Testers:
Danilo Castillo , Rodrigo Gutiérrez , Lucas Contreras .
Referencias
(1992) Deutsch, C., Journel, A. GSLIB: Geostatistical Software Library and User’s Guide
(2008) Emery, X. “A turning bands program for conditional co-simulation of cross-correlated Gaussian random fields.” COMPUTERS & GEOSCIENCES.
(2017) Cáceres, A., Valenzuela, D. and Pola, D. “GPGPU-based parallel variogram calculation and automatic model fitting.” GEOMIN MINEPLANNING.